Content
2019. 5. 21.
수도권 신도시 개발과 지속가능한 지방도시 재생
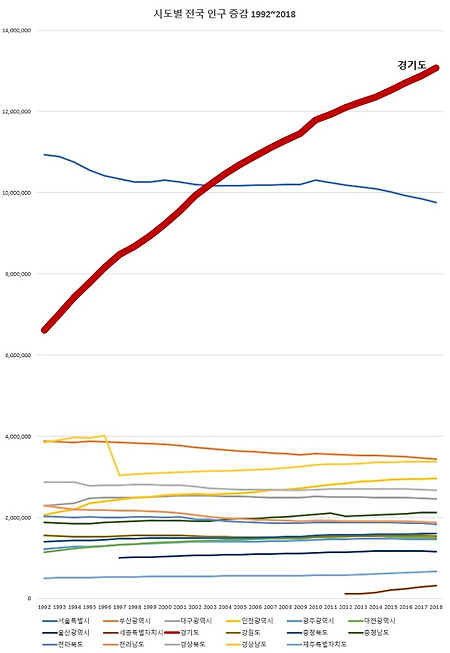
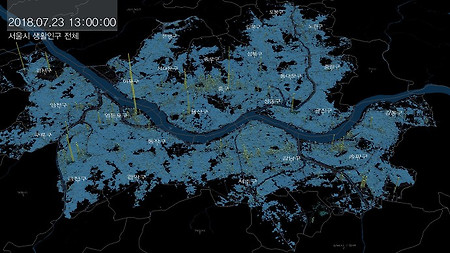
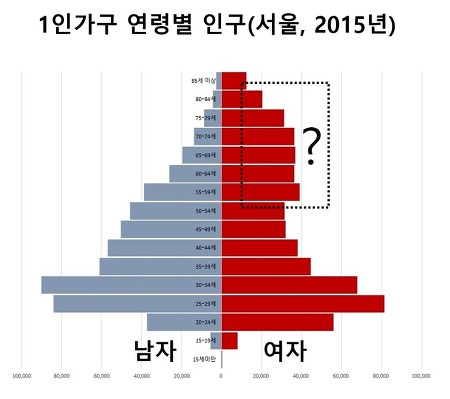
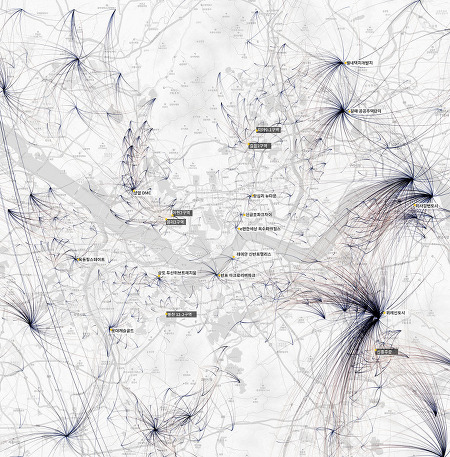
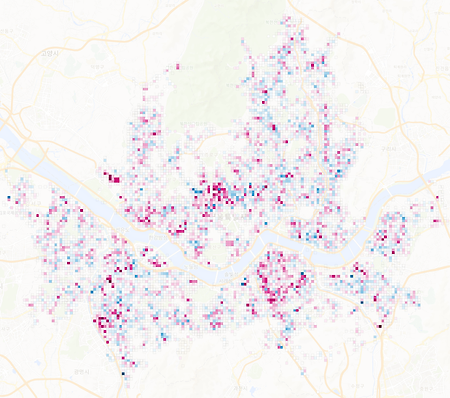
경기도 인구만 엄청나게 늘어났다. 지방도시 소멸이나 축소도시와 같은 말들이 오가는 요즈음, 시도별 인구증감을 보면 선 하나가 아주 두드러지게 눈에 들어온다. 그건 바로 경기도의 인구 증가선인데 1992년의 660만명에서 2018년에 1300만명으로, 26년동안 640만명이나 늘어났다. 거의 두배에 가까운 수치다. 같은 기간동안 전국 인구가 730만명 늘어난 점, 그리고 우리나라 지도에서 경기도가 차지하는 면적을 함께 생각해보면 1990년대 이후에 얼마나 수도권으로 인구가 집중되었는지 알 수 있다. 1990년대는 분당, 일산, 평촌, 산본, 중동과 같은 1기 신도시에 사람들이 입주하기 시작하던 시기이기도 하다. 경기도와 서울의 인구가 워낙 많은 탓에 다른 시도의 인구들이 고만고만해 보인다. 그렇다면 두 시..