
서울시에서 '생활이동' 데이터를 공개했다. KT의 휴대폰 시그널을 바탕으로 언제 어디서 어디로 어떤 사람들이(성연령) 이동했는지에 대한 데이터다.
서울 열린데이터광장
서울 생활이동 인구란? 서울 안에서 이동하거나 서울 외부에서 서울로 오고 간 이동으로 통근, 통학, 쇼핑, 여가 등 행정수요를 유발하는 모든 이동
data.seoul.go.kr
공개된 형식은 한 달을 기준으로, 요일별, 시간대별, 행정동별, 성별, 연령별 이동량이 있는데, 부가적인 속성을 통해 출근 혹은 통학 이동인지도 알 수 있다. 서울시 빅데이터 캠퍼스에서는 좀 더 상세한 단위의 데이터를 다룰 수 있다고 한다.
이렇게 출발지와 도착지가 있어, 선으로 그릴수 있는 데이터를 OD(Origin-Destination) 데이터, 혹은 플로우(flow) 데이터라고 부른다. 이런 데이터의 시각화에 대해서는 전에 한번 이곳에서 다룬 적 있다.
OD 시각화 1 : 여러가지 시도
지도 위에 데이터를 표현할 때 아주 까다로운 대상 중 하나는 OD 데이터다. Origin-Destination 데이터는 지도 위의 두 지점을 선으로 이어야 한다. 노드와 링크가 있는 추상공간 위의 네트워크 시각화
www.vw-lab.com
OD 시각화 2 : 전국 인구 순이동
앞의 글에서 여러가지 사례를 들어 OD 시각화에서 고민했던 점들을 썼다면, 이번에는 전국 인구 순이동 시각화를 조작해보면서 설명해보겠다. 앞의 글이란 이것 OD 시각화 1 : 여러가지 시도 지도
www.vw-lab.com
여기서는 생활이동 데이터를 열어보고, 기본적인 집계를 두어개 해본 뒤, Qgis에서 스타일을 적용하여 화살표로 그려보겠다. 내용보다는 방법에 대해서 주로 다룬다. R과 Qgis의 기본적인 사용법을 알고 있어야 하며, 기초적인 내용은 다루지 않는다.
데이터 개요
맨위의 링크에서 2021년 6월 데이터를 내려받았다. 압축을 풀면 약 7GB 용량을 파일을 확인할 수 있다.

열어보면 위와 같다. 녹색으로 표시한 부분은 다음과 같은 의미다.
2021년 6월 일요일 12시~12시 59분 사이에 서울 관악구 난향동(1121071)에서 서울 금천구 시흥3동(1118059)으로 55세~59세 사이의 여성이 3.28명 이동했다. 이동유형은 야간상주지에서 주간상주지로의 이동(HW)이다. 학교일수도 있지만 나이를 고려하면 출근일 가능성이 크다. 이동한 사람들의 평균 이동 시간은 약 10분~19분 사이의 값이다.
밑을 보면 별표도 있는데 3명 이하는 개인정보 비식별화의 차원에서 별표로 표시했다. 아래에서 이 인원들을 일괄적으로 2명으로 간주하여 다시 되살릴 예정이다. (1명, 2명, 3명 중 가운데 값인 2명을 택했다)
데이터 읽기
데이터를 읽어보자.
library(dplyr)
library(data.table)
library(ggplot2)
library(lubridate)
library(sf)라이브러리는 위의 다섯가지를 사용했다.
대부분 많이 쓰는 것들이고, sf는 데이터를 shape 파일로 저장할때 필요하다.
이제 데이터를 읽어보자.
폴더는 적절히 나누어 설정하면 된다.
srcFolder <- "A:/work/202109_서울시생활이동공개/data/"
gisFolder <- "A:/work/202109_서울시생활이동공개/gis/"
imageFolder <- "A:/work/202109_서울시생활이동공개/image/"
fileName <- paste0(srcFolder, "생활이동_행정동_202106.csv")
#RAM 8GB정도
system.time(raw <- fread(fileName,
quote="\"", #encoding="unknown",
select = c(1:10),
na.strings = c("\"*\"",NA),
colClasses = list(character = c(2,3,6, 8),
integer=c(1, 4, 5, 7), numeric = c(9,10)),
col.names = c('yyyymm','yoil','et','oricd','descd',
'gender', 'age', 'movetype', 'triptime', 'popu'),
sep = ",", header = TRUE, stringsAsFactors = FALSE, nThread = 20
)
)데이터의 크기가 7GB라서, 작다면 작고 크다면 큰 사이즈인데, 컴퓨터의 RAM이 32GB 이하인 사람들은 다루기에 약간 부담스러울 수도 있다.
일단 데이터를 읽어들이면 기본적으로 10GB정도 사용한다.
용량과 처리 속도에 약간 신경을 써야 하기 때문에, 여기서는 레퍼런스 형식으로 변수를 다루면서 cpu 병렬 처리를 하는 data.table의 문법을 사용할 예정이다. 레퍼런스 형식에 대한 설명은 cpp와 같이 검색하면 많이 찾을 수 있다. 데이터를 복사하면서 작업하지 않고 자기 자리에서 고쳐나가기 때문에 ram의 사용량이 적고, 복사 시간이 절약되므로 속도도 빠르다.
fread 함수를 이용하면 data.table 형식으로 바로 읽어들일 수 있다. data.table은 data.frame을 다루는 dplyr 문법도 사용 가능하지만, dplyr은 기본적으로 싱글 프로세서를 사용하기 때문에 퍼포먼스를 제대로 살리기는 어렵다. 이 정도 용량을 group_by로 처리하다보면 꽤 답답할때가 많다.
옵션을 여러개 달아놓았다.
select를 이용해서 일부분만 읽어들일 수 있는데, 읽어들이는 속도도 컬럼의 수에 거의 비례해서 줄어든다. 일단 여기서는 모두 읽었다.
컬럼들의 변수 형식은 자동 처리에 맡기지 말고, 위처럼 직접 지정해주는 것을 권장한다.
원천 데이터의 컬럼이름이 한글이므로 영문으로 미리 바꿔준다.
'popu'라고 표시된 곳이 바로 앞에서 잠시 언급한 이동량인데, 3이하가 별표(*)로 처리되어 있으므로, 미리 그 값을 NA 로 읽어들이면 편하다. 그래야만 데이터 형식도 character이 아니라 numeric으로 유지할 수 있다. 이런 내용을 지정한 부분이 바로 [na.strings] 이다.
현재 모든 데이터가 큰 따옴표로 감싸져 있으므로 위와 같이 약간 복잡하게 표현했다.
이제 데이터를 읽었으면 NA값을 2.0으로 대체하자.
raw[is.na(popu), popu := 2.0]
##자리수 일치
raw[oricd<100000, oricd := oricd*100]
raw[descd<100000, descd := descd*100]그리고, 공개된 생활이동 데이터는 서울 인천 경기의 경우 7자리의 읍면동코드값을 할당되어 있는데, 나머지 지역은 5자리의 시도코드가 할당되어 있다. 7자리로 맞춰주기 위해 위와 같이 변환한다.
아마도 많은 사람들이 위와 같은 data.table 문법에 익숙하지 않을 것 같다. 같은 처리를 dplyr 형식으로 해도 되는데, 위의 형식을 한번 써보면 처리 속도 차이가 워낙 커서 포기하기가 힘들다. 0.1초와 1초는 큰 차이라고 체감하기 어렵지만 10초와 100초는 정말 큰 차이이기 때문이다.
https://raw.githubusercontent.com/rstudio/cheatsheets/master/datatable.pdf
data.frame을 다루는 dplyr에 익숙한 사람이라면, 위의 링크를 참고하여 어렵지 않게 따라해 볼 수 있을 것 같다. 사실 이 글도 계속 위의 문서를 찾아보면서 쓰고 있다.
요일별 이동량 집계 1
data <- copy(raw)이렇게 사본을 하나 떠 놓으면 데이터를 처리할 준비를 모두 마친 셈이다.
data.table은 자기 자신을 바꾸므로 원본 데이터를 다시 읽지 않기 위해 저렇게 했다. copy 함수를 쓰지 않고 그냥 바로 대입해버리면 reference 형식이 되어 사본을 바꿔도 원본 역시 변경되므로 주의하자.
데이터를 검증할 겸, 먼저 요일별로 이동량을 집계해보자.
system.time(dataYoil <- data[, .(popu = sum(popu)), by = .(yoil)])
ggplot(data=dataYoil, aes(x=yoil, y=popu/1000))+#, fill=)) +
geom_bar( stat ="identity",position ="dodge")+
scale_x_discrete(limits=c("월","화","수","목","금","토","일")) +
labs(x="요일", y="이동량(천명)") +
theme_bw() +
theme(strip.text = element_text(size=15),
plot.title = element_text(size=15),
legend.title = element_text(color = "black", size = 25),#, face="bold"),
legend.text = element_text(color = "black", size = 20),#, face="bold"),
legend.position = "bottom",#c(0.1,0.8),
axis.text.x = element_text(size=20,angle=0, vjust=0.5),
axis.text.y = element_text(size=20,hjust=1),
axis.title = element_text(face = "bold", size = 20, color = "black")
)
yoil을 그룹으로 해서 popu를 집계하는 첫 줄을 실행하면, 아래와 비슷한 내용이 보인다.
system.time(dataYoil <- data[, .(popu = sum(popu)), by = .(yoil)])
사용자 시스템 elapsed
24.92 1.14 2.93싱글 프로세서로 돌리면 24.92초가 걸렸겠지만 data.table의 문법은 별다른 설정없이도 멀티 쓰레드로 처리하므로 2.93초가 걸렸다.
이제 ggplot로 이동량을 그려보면....

뭔가 좀 이상하다. 화요일과 수요일만 저렇게 많다는건 보편적 상식을 약간 벗어난다.
그래서 달력을 보니....

6월은 화요일과 수요일이 5일씩이고 나머지는 4일씩이다.
아하. 요일별로 그대로 집계했을테니 데이터가 위처럼 차이난 것이다. 그렇다면 요일의 수를 세어서 나누어 주어야 요일별 이동량을 제대로 비교해 볼 수 있겠다.
요일별 이동량 집계 2 - 요일 수 계산해서 나누기
#2021년 6월의 요일별 개수 세기
yoilCount <- data.table( yyyymmdd = seq(ymd("20210601"), ymd("20210630"), by="days")) %>%
mutate(yoil = as.character(wday(yyyymmdd, label = TRUE))) %>%
group_by(yoil) %>%
tally()
yoilCount <- as.data.table(yoilCount)날짜를 일별로 발생시켜서 데이터 테이블을 만들고 요일별로 수를 집계했다. 처리 과정중에 data.frame이 되어버려서, 마지막에 다시 data.table로 변환했다.
위의 과정 역시 모두 다 data.table의 문법으로 할 수도 있지만, 용량이 작은 데이터라, 그냥 익숙한 방식으로 처리했다. 마지막에 한 줄 더 써서 data.table로 바꾸는게 작업속도가 더 빠르기 때문이다. 어떤 과정을 거칠 것인가는 결국 생산성의 문제다.
dataYoil[yoilCount, on = .(yoil=yoil), count := i.n]
dataYoil[, popu := popu / count]이제 요일을 매개로 두 데이터를 조인하고, 요일의 수로 나누어 요일별 하루의 총 이동량을 계산했다.
다시 그려보자.
ggplot(data=dataYoil, aes(x=yoil, y=popu))+#, fill=)) +
geom_bar( stat ="identity",position ="dodge")+
geom_text(aes(label=scales::comma(as.integer(popu))),
hjust = 0.5, vjust = 0, position=position_dodge(width=1),
angle = 0,
size=6
#check_overlap = TRUE
)+
scale_y_continuous(labels = scales::comma) +
scale_x_discrete(limits=c("월","화","수","목","금","토","일")) +
labs(x="요일", y="이동량") +
theme_bw() +
theme(strip.text = element_text(size=15),
plot.title = element_text(size=15),
legend.title = element_text(color = "black", size = 25),#, face="bold"),
legend.text = element_text(color = "black", size = 20),#, face="bold"),
legend.position = "bottom",#c(0.1,0.8),
axis.text.x = element_text(size=20,angle=0, vjust=0.5),
axis.text.y = element_text(size=20,hjust=1),
axis.title = element_text(face = "bold", size = 20, color = "black")
)
ggsave(paste0(imageFolder,"00. 요일별 이동량.png"),
antialias = "default", width = 300, height = 200, unit = c("mm"), dpi = 200)

이번에는 각각의 막대에 숫자도 표시해보았다.
금요일의 이동량이 가장 많고, 그 다음은 수요일이다. 이동량으로 보니 일요일 낮에 차가 덜 막히는게 이해가 된다.
요일별로 데이터를 처리할 때 평일과 주말로 많이 구분하는데, 사실 토요일과 일요일은 꽤 다르다. 특히 이동량에서 그러한데, 대중교통량도 평일이 100이라 할 때 토요일과 일요일이 각각 80과 60만큼 차이난다.
성별, 연령별, 요일별, 시간대별 이동량 그래프
이번에는 성별 연령별 요일별 시간대별 이동량 그래프를 그려보자.
다시 사본을 떠서 작업한다.
data <- copy(raw)
#변환을 위한 참고 변수
yoilRef <- data.table(yoil = c("월","화","수","목","금","토","일"),
yoilcode = c("평","평","평","평","평","토","일"))
#평일, 토요일, 일요일로 대체
data[yoilRef, on = .(yoil=yoil), yoil := i.yoilcode]
#10세 연령별로 변환
data[, age := as.integer(age/10)*10]요일들을 평일/토요일/일요일의 3개로 구분하여 데이터를 변환한다.
5세 연령별 구분을 10세로 단순화 하여 보기로 한다.
이제 데이터를 집계한다. 요일별, 도착시간대별, 성별, 연령별로 구분한다. (yoil, et, age, gender)
system.time(dataTimeAgeGender <- data[, .(popu = sum(popu)),
by = .(yoil, et, age, gender)])
yoilCount <- data.table( yyyymmdd = seq(ymd("20210601"), ymd("20210630"), by="days")) %>%
mutate(yoil = as.character(wday(yyyymmdd, label = TRUE))) %>%
left_join(yoilRef, by="yoil") %>%
group_by(yoilcode) %>%
tally()
yoilCount <- as.data.table(yoilCount)
dataTimeAgeGender[yoilCount, on = .(yoil=yoilcode), count := i.n]
#요일별 평균
dataTimeAgeGender[, popu := popu /count]요일 수를 다시 세고, 평일, 토요일, 일요일의 수를 센다.
그리고 집계 데이터와 조인하여 요일별 하루 평균 이동량을 센다.
#양쪽 시각화를 위해 여성은 음수로
dataTimeAgeGender[gender=="F", popu := -popu]양쪽 팔처럼 뻗은 막대 그래프를 그리기 위해 한쪽 성별을 음수로 대체한다.
숫자를 '만'단위로 표시하는 함수는 아래 적힌 링크를 참고했다.
#x축을 "만"단위로 표현하는 함수
#https://lumiamitie.github.io/r/visualization/ggplot2-scale-label/
label_ko_num = function(num) {
ko_num = function(x) {
new_num = x %/% 10000
return(paste(abs(new_num), '만', sep = ''))
}
# vapply를 쓰고 싶지만 가끔 문자열대신 NA가 출력되는 경우도 있으니
# 여기서는 간단하게 sapply를 적용
return(sapply(num, ko_num))
}
그럼 이제 그래프를 그려보자.
ggplot(dataTimeAgeGender %>%
filter(age!=0 & age!=80), mapping = aes(x=et, y=popu, fill=gender)) +
geom_bar(aes(y=popu), stat ="identity")+#, position ="dodge")+
facet_grid( yoil~age, scales="free_y")+
labs(x="도착시각", y="성별 연령별 이동인원") +
theme_bw()+
theme(strip.text = element_text(size=20),
plot.title = element_text(size=15),
legend.title = element_blank())+
scale_x_discrete(limits=rev(levels(as.factor(dataTimeAgeGender$et)))) +
scale_y_continuous(labels=label_ko_num) +
coord_flip(ylim=c(-200000,200000))
ggsave(paste0(imageFolder,"01. 요일별성별연령별도착시각별 이동량.png"),
antialias = "default", width = 300, height = 200, unit = c("mm"), dpi = 200)
결과는 아래와 같다.

사실 이게 꽤 재미있는 그래프인데, 데이터를 구분한 속성만큼의 이야기가 담겨 있다.
맨 아래 평일만 보자.
가장 왼쪽이 10대의 시간대별 이동이다. 붉은색이 여성, 푸른색이 남성이다.
10대의 이동량은 남녀 대칭이다. 똑같다. 똑같이 중학교 고등학교에 간다.
20대도 이동량의 변화는 비슷한데 양이 좀 다르다. 군대에 가셔 빠졌을 만큼보다 좀 더 차이가 나는 것 같은데, 서울에 남성보다 여성이 많아서 그럴 수도 있고, 20대의 경우 여성들보다 남성이 덜 이동하기 때문에 그럴 수도 있다. 원인은 더 알아봐야 하겠지만, 일단 이동량이 차이난다는 사실을 알 수 있다.
30대로 가면서 대칭인 듯 하지만 오전 출근 시간대가 약간 다르다. 40대로 가면서 남성이 좀더 오전에 많이 움직인다. 혼인을 하고 가정을 이루면서 성별 역할 분담이 차이나서 그럴 수도 있고... 정확한 원인은 더 조사를 해봐야 겠지만, 일단 20대까지와는 달리, 이동에 관한한, 남녀의 삶이 확실히 달라지고 있다.
이 데이터의 시간 정보는 이동 도착시간 기준인데, 혹시라도 빅데이터 캠퍼스에 들어가서 이동 출발 시각으로 데이터를 집계해볼 기회가 있다면 더 재미있는 사실을 발견할 수 있다. 오전 시간대의 피크 자체가 남녀간에 1시간이 어긋나기 때문이다. 서울시 생활이동 데이터 웹페이지에서 내려받을 수 있는 [서울생활이동데이터_사용설명서.pdf]의 22페이지에서 이 내용을 확인할 수 있다.
평일에는 남녀의 삶이 60대와 70대까지도 달라보인다. 그나마 일요일에는 비슷하다. 6일동안 벌어지다가 하루동안 가까워지는게 대한민국 남녀의 삶인가보다.
20대를 보면 22시에 이동량이 잠시 증가한다. 밤시간 가게 문을 닫는, 거리두기 정책 때문인 것 같다. 다른 연령대보다 20대에서 좀 더 두드러지게 나타난다.
10대의 경우 거리두기 때문일지, 학원 때문일지는 잘 모르겠다.
이동 속성으로 필터링해서 그려볼 수도 있다.
system.time(dataTypeTimeAgeGender <- data[, .(popu = sum(popu)),
by = .(movetype, yoil, et, age, gender)])
dataTypeTimeAgeGender[yoilCount, on = .(yoil=yoilcode), count := i.n]
#요일별 평균
dataTypeTimeAgeGender[, popu := popu /count]
#여성은 음수로
dataTypeTimeAgeGender[gender=="F", popu := -popu]데이터를 집계할 때 'movetype'을 하나 더 추가했다.
사람들의 체류장소를 야간상주지(H)와 주간상주지(W), 그리고 나머지 모든 장소인 기타(E)의 세 가지로 구분했다. 체류지와 체류지를 연결하면 이동이 되므로 HW는 야간 상주지에서 주간 상주지로의 이동이다. 출근이나 등교에 해당하는데, 낮에 정기적으로 같은 장소에 가서 몇 시간씩 보낸다면 출근이 아니라도 HW에 집계될 수 있다.
이동은 그래서 3 x 3 = 9 개 유형이다.
HH, HW, HE, WH, WW, WE, EH, EW, EE
야간 상주지와 주간 상주지는 몇개씩 추정되었을 수 있다. 그 달 중간에 이사를 갔을 수도 있고, 혹은 장거리 직장 근처에 숙소가 더 있어서 일주일에 2일/5일 등으로 머무른다면 두 곳 다 야간상주지로 추정되었을 수도 있다. 그러므로 HH의 이동이 나타나게 된다. WW 역시 마찬가지다. 주간에 학교에 갔다가 학원을 가는데 학원에서 머무르는 시간이 꽤 많다면 학원 역시 주간상주지로 추정되었을 수 있다. 그래서 많지는 않지만 WW의 이동이 나타나게 된다.
이제 그러면 출근이나 등교 이동을 보자.
##출근이나 등교 이동
ggplot(dataTypeTimeAgeGender %>%
filter(movetype=="HW") %>% filter(age!=0 & age!=80),
mapping = aes(x=et, y=popu, fill=gender)) +
geom_bar(aes(y=popu), stat ="identity")+#, position ="dodge")+
facet_grid( yoil~age, scales="free_y")+
labs(x="도착시각", y="성별 연령별 이동인원") +
theme_bw()+
theme(strip.text = element_text(size=20),
plot.title = element_text(size=15),
legend.title = element_blank())+
scale_x_discrete(limits=rev(levels(as.factor(dataTypeTimeAgeGender$et)))) +
scale_y_continuous(labels=label_ko_num) +
coord_flip(ylim=c(-160000,160000))
ggsave(paste0(imageFolder,"02. 요일별성별연령별도착시각별 이동량_HW.png"),
antialias = "default", width = 300, height = 200, unit = c("mm"), dpi = 200)

확실히 평일 오전 시간대에 많고, 토요일이나 일요일은 적다. 거리두기 지침에 따라서 등교를 하거나 그렇지 않은 시기의 10세~19세를 비교해보면 확실하게 차이가 날 것 같다.
이번에는 어디선가 집으로 돌아오는 이동들을 추출해봤다.
##집으로 돌아오는 이동
ggplot(dataTypeTimeAgeGender %>%
filter(movetype=="WH" | movetype=="EH") %>% filter(age!=0 & age!=80),
mapping = aes(x=et, y=popu, fill=gender)) +
geom_bar(aes(y=popu), stat ="identity")+#, position ="dodge")+
facet_grid( yoil~age, scales="free_y")+
labs(x="도착시각", y="성별 연령별 이동인원") +
theme_bw()+
theme(strip.text = element_text(size=20),
plot.title = element_text(size=15),
legend.title = element_blank())+
scale_x_discrete(limits=rev(levels(as.factor(dataTypeTimeAgeGender$et)))) +
scale_y_continuous(labels=label_ko_num) +
coord_flip(ylim=c(-120000,120000))
ggsave(paste0(imageFolder,"02. 요일별성별연령별도착시각별 이동량_집으로.png"),
antialias = "default", width = 300, height = 200, unit = c("mm"), dpi = 200)
시간대별 변화율을 눈으로 어림짐작해보면, 20대의 곡률만 약간 다르다. 마치 손으로 가운데 심을 잡고 밑으로 누르면서 짜내고 있는 것 같다. 20대의 경우 좀 더 밤까지 있으려는 경향이 강한 것 처럼 보인다. 친구를 만나거나 연인을 만나는 등 여가 시간을 보내고 있을 수도 있지만, 공부를 하거나 원치않는 야근을 하고 있을 수도 있다. 역시 원인은 조사해봐야 겠지만, 현상에 대한 사실 확인만으로도 여러가지 질문을 해볼 수 있는 좋은 출발점이 된다.
연령대가 증가하면서 집으로 돌아오는 시간대가 점차 올라가는 현상도 재미있다.
shape 파일로 변환
기본 집계는 여기까지 하고, 이제 지도로 옮겨보자.
data <- copy(raw)
#평일, 토요일, 일요일로 대체
yoilRef <- data.table(yoil = c("월","화","수","목","금","토","일"),
yoilcode = c("P","P","P","P","P","H","H"))
data[yoilRef, on = .(yoil=yoil), yoil := i.yoilcode]
system.time(dataODgenderMovetype <- data[, .(popu = sum(popu)), by = .(yoil, oricd, descd, movetype)])다시 사본을 떠서 작업한다.
여기서는 일단 요일, 출발지, 도착지, 이동유형까지만 그룹핑하여 집계해보자.
요일같은 경우 나중에 shp 파일의 컬럼 이름이 되므로, 평일(P)와 휴일(H)으로만 구분하여 영문으로 바꿔둔다.
yoilCount <- data.table( yyyymmdd = seq(ymd("20210601"), ymd("20210630"), by="days")) %>%
mutate(yoil = as.character(wday(yyyymmdd, label = TRUE))) %>%
left_join(yoilRef, by="yoil") %>%
group_by(yoilcode) %>%
tally()
yoilCount <- as.data.table(yoilCount)
dataODgenderMovetype[yoilCount, on = .(yoil=yoilcode), count := i.n]
#요일별 평균
dataODgenderMovetype[, popu := popu /count]
#출발도착이 같은 경우 삭제
dataODgenderMovetype <- dataODgenderMovetype[oricd!=descd,]역시 평일과 토일요일 수를 세서 하루 평균치를 구한다.
출발지와 도착지를 선으로 그릴 것이므로, 마지막에 출발도착 행정동이 같은경우 삭제한다.
지도에 그리기 위해서는 좌표가 있어야 하는데, 미리 경계 중심점들을 작업해서 깃허브에 올려놓았다.
아래의 경로대로 읽으면 된다.
##행정경계 중심점을 읽어들인다.
fileName <- "https://raw.githubusercontent.com/vuski/admdongkor/master/ver20180301/InnerCentroid.tsv"
system.time(center <- fread(fileName,
#quote="\"", #encoding="unknown",
encoding="UTF-8",
select = c(1:9),
#select = c(1),
#na.strings = c("_",NA),
colClasses = list(character = c(2:7),
integer=c(1,8,9)),
sep = "\t", header = TRUE, stringsAsFactors = FALSE
)
)
dataODgenderMovetype[center, on = .(oricd=admcd), ':='(sx = i.x, sy=i.y)]
dataODgenderMovetype[center, on = .(descd=admcd), ':='(ex = i.x, ey=i.y)]생활이동 데이터에 사용된 행정구역은 2018년 3월 버젼이다. 당분간 공개되는 데이터들끼리 비교를 해야 하므로 한동안은 그대로 유지될 것 같다.
위에서는 행정구역 경계 중심점들을 읽어서 출발지 좌표를 sx, sy, 도착지 좌표를 ex, ey로 조인시켰다.
UTMK(EPSG:5179) 좌표계를 사용했다.
이제 shp 파일로 만들기 위한 본격 준비를 시작한다.
#dcast 로 데이터 형식 재배열
temp <- dcast(dataODgenderMovetype, sx+sy+ex+ey+oricd+descd~movetype+yoil,
value.var = "popu", fill=0)
## 곧바로 shp으로 보내면 너무 많으므로 적절히 필터링 함
temp[, sumH := rowSums(.SD), .SDcols = c(7,9,11,13,15,17,19,21,23)] ##휴일 이동 합
temp[, sumP := rowSums(.SD), .SDcols = c(8,10,12,14,16,18,20,22,24)] ##평일 이동 합
#필터링
temp <- temp[sumH>10.0 | sumP > 10.0]
#일련번호 붙이기
temp[, id := 1:.N]dcast를 통해 데이터 배열을 조정한다. 제대로 변환되었다면 아래 그림과 같아진다.

dcast 옵션을 보면, 이동유형과 요일들이 결합되어 총 9개 유형 x 2개 요일 = 18개 컬럼으로 데이터가 재집계되었음을 알 수 있다. 라인 수가 너무 많으므로 평일과 휴일 총합계 기준 10명 이상인 지역들만 필터링한다.
이 데이터에는 좌표와 속성이 같이 들어가 있는데, 이제 좌표 따로, 속성 따로 분리해둔 후, 좌표 값만 있는 테이블을 먼서 공간 데이터로 변환하고, 이후에 다시 속성을 결합해서 완성할 예정이다. 결합 key가 되는 컬럼은 위에서 붙인 일련번호 id 컬럼이다.
shp로 바꾸려면 data.table이 아닌, data.frame 형식이어야 에러가 나지 않는데, 그냥 as.data.frame 해도 안되길래 아래와 같은 임시 편법으로 데이블의 메타 속성인 attr 부분을 없애주었다.
temp <- temp %>% group_by(id) %>% ungroup()
일단 아래처럼 좌표 부분만 분리해둔다. 1열부터 4열까지 꼭 좌표값이 들어있어야 한다. 코드의 뒷부분과 관련된다. id를 맨 앞으로 빼지 말라는 의미다.
#line 도형 부분만 추출
#좌표를 1,2,3,4열에 두는 것이 중요함
#아래 부분 row[1:4]와 연관됨
geom <- temp %>% select(sx, sy, ex, ey, id)
아래 부분이 lineString 형식의 gis용 shape 파일로 변환하는 핵심적인 부분이다.
솔직히 무슨 내용이 흘러가고 있는지 눈치로 적당히 분위기 파악하는 만큼 이상은 잘 모르겠다. 인터넷 이곳저곳을 참고하여 작성한 것인데...., 어쨌든 동작한다.
##### 여기부터 line shp 파일 만들기
system.time(
rows <- split(geom, seq(nrow(geom)))
)
lines <- lapply(rows, function(row){
lmat <- matrix(unlist(row[1:4]), ncol = 2, byrow = TRUE)
st_linestring(lmat)
})
lines<-st_sfc(lines)
lines_sf <- st_sf('id'=temp$id,
'geometry' = lines, crs = 5179)아래 부분에서는 숫자가 중요하다.
matrix(unlist(row[1:4]), ncol = 2, byrow = TRUE)
1:4는 라인 시작점 xy좌표 종료점 xy좌표가 순서대로 있는 컬럼 번호를 써줘야 하며, ncol=2는 항상 2가 되어야 한다.
마지막 줄 좌표계는 EPSG:5179 를 의미한다.
마지막 줄에 'id'=temp$id 부분을 보면 알 수 있지만, 굳이 뒤에서 join 하지 않고, 테이블 행의 순서만 같다면, 여기서 바로 좌표와 속성을 결합해버려도 된다. 18개를 저렇게 적기에는 너무 많으므로, 여기서는 join 하는 방식을 택했다.
거의 다 했다. 이제 속성과 결합해 준다. 5:27 부분은 당연히 각자 export하고자 하는 컬럼 번호를 확인하고 지정해줘야 한다.
#다시 id 값을 매개로 원래 속성과 조인
lines_sf <- lines_sf %>%
left_join(temp[,c(5:27)], by = "id")
#처음에 oricd와 descd를 숫자형식으로 읽어주었으므로 다시 문자열로 변환
#qgis에서 like 구문으로 필터링 하기 위함
lines_sf$oricd <- as.character(lines_sf$oricd)
lines_sf$descd <- as.character(lines_sf$descd)
###########shp로 저장
st_write(lines_sf, paste0(gisFolder,"00_평일휴일별이동유형별.shp"),
driver="ESRI Shapefile") # create to a shapefile
마지막에 st_write로 저장하면 끝이다. 곧바로 qgis에서 열린다.
배경지도 준비
qgis에서 그리기 위해서는 배경지도도 필요할 것 같다.
GitHub - vuski/admdongkor: 대한민국 행정동 경계 파일
대한민국 행정동 경계 파일. Contribute to vuski/admdongkor development by creating an account on GitHub.
github.com
위의 링크에 필요한 shp 파일들 3개를 만들어두었다.

압축을 풀면 나오는 [생활이동배경지도.shp]는 배포되는 데이터 형식에 맞춰두었다. 서울인천경기는 읍면동 단위, 나머지는 시도 단위의 폴리곤이다.
[생활이동배경지도_시군구_서울인천경기.shp]는 서울인천경기 부분만 시군구 경계로 따 놓았다.
[행정동경계_20180301_시도.shp]는 전국 경계를 시도단위로 따 놓았다.
이 파일 3개를 적절히 잘 활용하면 아래와 같은 지도를 그릴 수 있다.

시군구 경계와 시도 경계는 면은 투명하게 두고 선만 칠하면 된다. 당연히 두 개 모두 생활이동배경지도.shp 보다 레이어상 위에 위치해야 한다.
선을 화살표로 만들기
이제 R에서 마지막에 만든 파일을 올려보자.

선들이 많으므로 위처럼 보인다. 이제 스타일을 적용할 차례다.
기본적인 내용은 아래 링크를 참고했다. 아래 내용을 따라하면서 약간만 변형하였다.
Flow maps in QGIS – no plugins needed!
If you’ve been following my posts, you’ll no doubt have seen quite a few flow maps on this blog. This tutorial brings together many different elements to show you exactly how to create …
anitagraser.com
위의 링크에도 설명이 있지만, 심볼에서 아래 단계처럼 형식을 만들어야 한다.

라인을 선택하고 오른쪽에 녹색 + 버튼을 클릭한 후, 심볼레이어 유형에서 '도형생성기'를 선택한다.
도형 유형은 위 그림과 같이 라인스트링/멀티라인스트링으로 두고, 빈 공간에 아래 내용을 적어야 한다.
difference(
difference(
make_line(
start_point($geometry),
centroid(
offset_curve(
$geometry,
length($geometry)/-9.0
)
),
end_point($geometry)
),
buffer(start_point($geometry), 0.01)
),
buffer(end_point( $geometry), 0.01)
)함수를 표현한 코드 문법은 잘 모르겠지만, 숫자들을 바꿔보면 형태가 어떻게 바뀌는지 확인할 수 있다.
그 다음에는, 아래 그림처럼 단계적 도형 생성 옵션 중 '화살표'를 선택해보자.

화살표 너비, 시작점 화살표 너비, 머리 길이, 머리 두께 등을 속성변수값에 기반하여 표현하는것을 권장한다.
화살표 너비 옵션은 아래처럼 두었다. 각자의 데이터 양에 맞게 숫자 등을 바꿔주면 된다.

나머지 세개의 표현값은 각각 아래 그림처럼 두었다.



이제 거의 끝났다.
위의 트리에서 마지막 단계인 [단순채우기]를 선택하고 표현식을 적절히 써 넣는다.

여기서는 양수와 음수값을 다르게 하는 표현식으로 마련해두었는데, 일단은 어디서 어디를 뺀 것은 아니므로 모두 붉은색으로 나오게 된다.
그래서 드디어 확인확인 누르고 빠져나와보자.

이런 그림이 나올 것 같다.
선들이 아직 너무 많으므로 적절히 필터링해낸다.

위에서 화살표 값들을 휴일 하루 평균값(sumH)으로 설정해주었으므로, ctrl-F로 필터링 할 때도 해당 값, 즉 이동량이 1000명 이상인 화살표들만 남겨 그려본다.
아래와 같은 지도가 된다.

필터링 옵션을 아래와 같이 추가해보자.
"sumH" > 1000 and "oricd" like '11120%'출발지가 은평구(11120)인 이동만 걸러내본다.

위의 이동들은 휴일평균값이다.
다른 지도도 그려보자.
일단 '레이어 복제'를 통해 별도의 파일 저장 없이 다른 필터링&스타일링을 위한 레이어를 마련한다.

방금 전에 셋팅해 둔 레이어에서 스타일을 복사한 후,
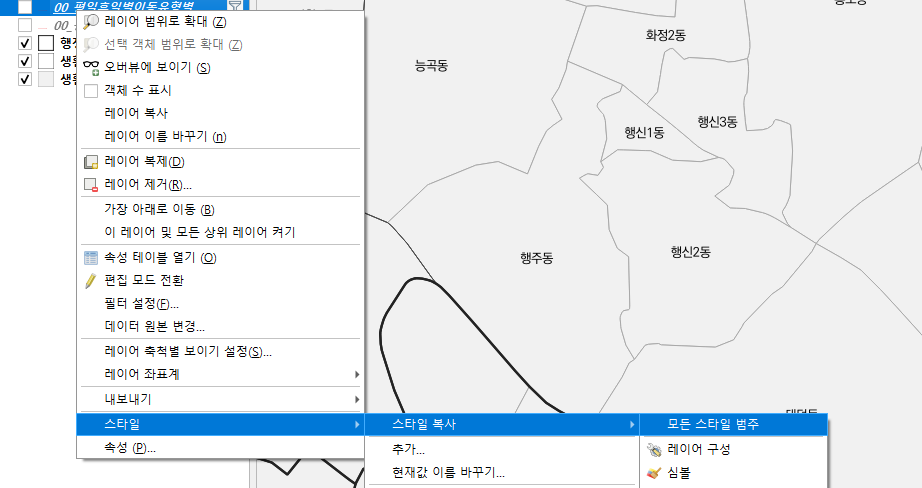
새로운 레이어에 붙여넣기 한다.

화살표 굵기 등은 어차피 다시 입력해야 한다. 아까의 옵션에 들어가 적절한 값으로 변경한다. 화살표 모양 관련 4곳과 색상 1곳 해서 총 5군데를 변경해야 한다.

여기서는 평일 출근량을 보기로 한다.
이번에는 필터링 조건을 아래와 같이 둔다.
"sumP" > 1000 and "descd" like '11140%'즉, 마포구(11140)로 출근하는 사람들의 경로 중 평일 하루 평균 1000명 이상인 곳들만 보여주기로 했다.

위의 그림처럼 인접지역에서의 출근량이 많음을 알 수 있다.
여의도에서 마포구 곳곳으로 출근하는 사람들이, 다른 인접지역보다 꽤 많아보인다.
확대하면 아래와 같은 화살표 모양을 볼 수 있다.

끝!
'Function' 카테고리의 다른 글
| 지구를 그려보자 (0) | 2021.10.29 |
|---|---|
| 스마트서울 도시데이터센서(S-DoT)기온 데이터 시각화 (6) | 2021.10.11 |
| 15분만에 전국 음식점 개폐업 지도 만들어보기 (4) | 2021.07.12 |
| OD 시각화 2 : 전국 인구 순이동 (0) | 2021.04.25 |
| OD 시각화 1 : 여러가지 시도 (3) | 2021.04.24 |



