
이 글에서는 국토교통부에서 공개중인 실거래가 데이터를 지도에 표시하기 위해 주로 좌표값을 연결하는 과정을 설명한다.
간단히 말해 '지오코딩'하는 과정 + 알파 정도가 되겠다. 형식적으로는 다음의 내용을 담고 있으며 실거래가 데이터를 예로 들어서 설명한다고 보면 된다.
- 법정동 주소 형식을 PNU 코드로 바꾸기
- PNU 코드의 좌표값 얻기
- 현재 존재하지 않는 과거 주소의 좌표값 얻기
- 한 좌표점으로 겹치는 좌표값 처리하기
- 전월세 전환율 적용시켜 월세를 전세가로 만들기
이 데이터를 처리하기 위해서는 어떤 파이썬이든 R이든 자바든 파일 입출력과 문자열 처리 정도는 할 수 있어야 한다.
세세한 디테일은 설명하지 않으므로, 혹시 설명이 부족한 부분이 있다면 각자 익숙한 언어와 도구에서 검색하기를 권한다.
그럼 하나씩 가 보자.
실거래가 데이터 상태 파악하기
일단 국토교통부의 실거래가 데이터를 받아야 한다. Open API를 사용할 경우 구글링을 통해 몇 가지 크롤러를 찾아볼 수 있다. 국토교통부 실거래가에서 직접 받을 경우 효율적으로 부지런히 작업하면 8시간 정도 걸린다.
2020년 3월 말까지의 데이터는 여기에 올려두었다.
https://github.com/vuski/RealEstateTransactionKorea
vuski/RealEstateTransactionKorea
부동산 실거래가. Contribute to vuski/RealEstateTransactionKorea development by creating an account on GitHub.
github.com
흠.. 얼굴만 좀 지울 수 없나.
실거래가 데이터는 총 11가지로 제공된다. 크게 나누면 매매와 전월세 두 종류다.
매매는 7종류다.
아파트, 연립다세대, 단독다가구, 오피스텔, 분양권, 상업업무용, 토지
전월세는 4종류다.
아파트, 연립다세대, 단독다가구, 오피스텔
단독다가구의 경우 전월세는 작은 금액 위주로 거래되는데, 매매는 그렇지 않다. 연면적이 큰, 그러니까 건물 하나 전체를 거래하는 경우도 꽤 있다.
분양권의 경우 같은 아파트단지와 묶어주면 매매가와 시계열 상으로 차이가 나는, 비슷한 성질의 데이터로 보아도 된다.
상업업무용과 토지의 경우 내용상 각각 다른 성격의 데이터로 다루어야 한다.
우리는 지오코딩을 하기로 했으므로, 내용은 좀 미뤄두고 다시 주소 기준으로 데이터를 구분해보자.
우선, 번지 단위의 상세 주소가 제공되는 경우
아파트 2종(매매/전월세), 연립다세대 2종, 오피스텔 2종, 분양권

비록 건물 단위 까지는 아니더라도 아파트 단지 기준으로 볼 때 전체 주소가 하나의 번지로 기록되어 있으며, 이러할 경우 연속 지적도가 있다면 좌표값을 구할 수 있다.
법정동(혹은 법정리) 단위까지만 제공되는 경우
단독다가구 2종, 상업업무용, 토지

헷갈리지 말자, 선거와 같이 사람을 다룰 때는 행정동, 부동산은 항상 법정동 기준이다. 도로명이 곁다리로 쓰여있기는 하지만, 도로명이 기존 주소체계를 완전히 대체할 수 없다. 왜냐하면 수많은 토지대장 등 재산 관련 문서들이 법정동 기준으로 기록되어 있고, 앞으로도 그래야만 하기 때문이다. 도로명 주소는 건물 기준이므로 건물이 사라지면 함께 없어진다. 그렇기 때문에 실거래가 데이터도 법정동 주소는 온전히 기록되어 있고 도로명 주소는 위에서와 같이 null 값이 있다.
법정동 단위까지만 제공되는 경우는 번지를 별표처리했다. 그런데 위의 예를 보면 5** 번지는 500번대 번지, 1***대 번지는 1000번대 번지라는 것을 추측할 수 있다. 사실 10-1을 1***으로 처리한 것일수도 있지만, 최대 자리수가 네자리인 것으로 보아 본번과 부번 중 본번만 별표처리하여 표기한 것 같다. 굳이 부번까지 특정하고자 하면 여러가지 데이터를 조합하여 찾아낼 수 있을 것 같기도 하지만, 일단 여기서는 공개한 수준까지만 처리하기로 한다.
주소의 시점은?
법정동이든 행정동이든 계속 변한다. 이게 지오코딩할 때 까다로운 점들 중 하나인데, 데이터의 시점을 확인하기 위해 알고 있는 몇몇 사실들을 이용하여 탐색해본다.

아하. 2006년도 거래인데 2018년에 이름을 얻은 미추홀구가 등장한다. 과거 주소를 현재 시점으로 바꿔놓았다는 점을 알 수 있고, 아마도 최근 시점(2020년 4월) 기준으로 바꾸어 놓았을 것이라 추측한다.
자, 여기서 한가지 문제가 발생할 수 있는데, 2006년에 존재했던 법정동과 번지인데 지금은 건물이(그래서 주소도) 존재하지 않는 경우다. 여기서 해당 법정동을 현재 법정동 주소로 단순 치환하여 게시할 경우 해독하는 입장에서는 완전히 암호가 되어버릴 수 있는데, 이건 뒤에서 다루기로 한다.
KEY값 뽑아내기
그러면 이제 지오코딩을 위한 첫번째 작업. 11개 데이터를 두 가지로 분류하여 주소들의 고유값들을 추출한다.
번지까지 있는 것들은 다음과 같이 key값을 만들어낸다.
[시군구 이름] + "\t" + [본번 네자리] + [부번 네자리]
데이터에 시군구라고는 써있지만 실제로는 읍면동리 수준까지 있다.
key 값을 만들 때 구분자(여기서는 tab 문자)를 넣어두면 나중에 다시 분리하기 편하다.
그리고 보통은 콤마를 구분자로 많이 쓰는데, 문자열 안에 콤마가 포함될 경우도 많이 있기 때문에 tab을 쓰는 것을 권장한다. 거의 대부분의 문서 안의 문자열에 tab은 포함되어 있지 않다.(그런데 놀랍게도 실거래가 데이터는 콤마를 구분자로 사용하면서도 tab이 문자열 안에 포함되어 있는 사례가 있었다)

2006년부터 2020년 3월까지, 그리고 7개의 데이터 유형에서 총 307,805개의 고유 번지 주소가 추출되었다. 본번과 부번을 합쳐 8자리 문자열을 만들었다. 숫자로 다루어서 앞의 0을 떼어버리면 PNU 코드 만들때 약간 귀찮아진다.
법정동까지 있는 것들은 [시군구 이름] 만으로 key 값을 만든다. 그리고 혹시 모르니 4개 유형에서만 뽑지 말고 11개 유형에서 모두 뽑아내기로 한다.
총 18,775개를 추출했다. (그림 생략)
한글 주소를 숫자 코드로 바꾸기
이제 한글로 된 주소를 숫자(법정동 코드 및 pnu 코드)로 바꾸자.
www.code.go.kr 에서 법정동 주소 코드를 다운 받는다.

과거에 존재했던 모든 법정동 코드와 주소가 있으며 존폐여부도 함께 있다.
그렇다면 이제 앞에서 뽑아낸 18,775개의 key값과 대조해서 법정동 코드를 찾아낸다. 각자 편한 환경에서 하면 되는데, 여기서는 수가 적으므로 그냥 엑셀을 이용했다. 기본적으로 trim() 으로 양끝 공백이 혹시 있으면 제거해주고 vlookup으로 찾아오면 금방 된다.

사실 금방 될 것 같지만 전혀 그렇지 않다. 깔끔하지 않다.
...
아-주 깔끔하지 않다.
위의 목록에서는 1차적으로 처리가 안된 것들을 필터링했다. 사실 이미 처리를 한 결과인데, 맨 처음에는 '처리전' 열을 제외한 나머지가 모두 비어있다고 생각하면 된다.
첫번째 보이는 불일치 사례는 실거래가 데이터에 '청룡리'로 되어 있고 법정동 코드에는 '청용리'로 되어 있는 경우다.
아주 많을 경우 유사 문자열로 매칭시키는 코드를 고안해봐야 하지만, 그렇게 많지 않아서 수작업으로 맞춰주었다.
물론, 단순한 이름 한 글자가 불일치하는 경우는 청룡리, 청용리처럼 쉽게 찾아서 매칭시킬 수 있는데, 그렇지 않은 경우도 있다.
원본에는 경상북도 김천시 남면 용전리인데 찾아보면 현재 김천시 율곡동인 경우다. 이유를 하나하나 알아내기는 시간이 걸리므로 주소가 변한 것이 확실하면 위의 표 같은 형식으로 매칭되지 않은 빈 칸들을 채워나간다.

위 처럼 존재하지 않는 법정동 주소를 포함한 원본 파일 내용들을 다시 추출하고, 카카오 맵 검색등을 통해 앞뒤 주변 정황을 보면 어렵지 않게 어느 주소로 변했는지 알아낼 수 있다.
고양덕양구 - 고양시 덕양구와 같은 불일치 문제는 한숨은 나오지만 몇 분안에 처리할 수 있다.
우리나라 주소에서 시군구 단위가 다시 하위 구를 갖고 있는 경우인데, 수원, 성남, 고양 등 경기도에 다수 있고 포항, 창원, 전주 등 지역 곳곳에 있다.
이런 경우는 주로 고양시덕양구(붙여쓰기)와 고양시 덕양구(띄어쓰기)로 표기되어 있는데, '고양덕양구'는 여기서 또 처음 만났다. 주소처리를 많이 하다보면 '고양시덕양구'처럼 붙여서 쓴 형태를 선호하게 된다. 그래야만 간단하게 공백을 기준으로 시도와 시군구, 그리고 읍면동이라는 세가지 위계를 분리해낼 수 있기 때문이다.
그래서 아래처럼 정리를 하면 된다. 바로 위에서 등장했던 그림이다.
결국 여기서 하고자 하는 것은 원본 파일의 법정동 주소에 대한 법정동 코드를 찾아내는 것이므로, 매칭되지 않는 '처리전' 주소에 대한 현재 시점의 표준주소를 찾고('처리후') 이 표준주소를 바탕으로 법정동 코드 자료에서 10자리 코드를 따오면 위의 표가 완성된다.
이제 '처리전' 열과 '법정동 코드' 열만 있으면 실거래가 원본 주소 문자열에서 법정동 코드를 뽑아낼 수 있다.
매칭 테이블은 다음과 같이 정리해 놓자. 데이터 원본에 있는 주소와 표준 주소 문자열, 그리고 법정동 코드 세 가지를 다 담아두어야 추후에 또 활용이 쉽다.

이번에는 아파트 등 번지까지 온전히 있는 주소들을 대상으로 PNU 코드를 만들어낼 차례다. 앞에서 언급한 고유 주소 307,805개를 대상으로 한다.

이건 어렵지 않다.
앞에서 A열과 B열을 완성한 셈이고, 지번은 원래 추출해서 나온 것들이니 문자열만 연결하면 된다.
대부분 대지이므로 10자리 코드와 8자리 지번 사이에 대지를 가리키는 '1'만 추가하여 19자리를 완성하면 된다.
pnu 코드는 [시도 2자리] + [시군구3자리] + [읍면동 3자리] + [리 2자리] + [대지 혹은 산 1자리] + [본번지 4자리] + [부번지4자리]의 총 19자리로 이루어진다.
(pnu 코드가 무엇인지 더 궁금하면 구글링해보자. 친절한 설명글이 많이 나온다)
C++이나 자바처럼 변수 타입을 지정해줄 수 있는 경우에는 문자열 대신 64비트 Integer 타입으로 저장하면 편리한 점이 많다. 온전히 숫자로 이루어졌으므로 8바이트만 있으면 내용을 모두 담을 수 있기 때문이다.
사실 여기까지 했으면 아직 지도에는 표현할 수 없지만, 동별로 데이터를 솎아보는 등 여러가지 분류 작업을 할 수 있다.
그래도 지도에 찍어보기로 했으니 좀 더 (많이) 해보자.
법정동 코드 값에 대응하는 좌표를 찾기
최종적으로 토지나 상업용 부동산들은 법정동으로 분류하여 지도에 찍어볼 예정이다. 그리고 지번이 있는 것들은 지번의 중심점에 찍어볼 것이다. 그러므로 드디어 지도가 필요한 차례가 되었다.
http://openapi.nsdi.go.kr/nsdi/index.do
국가공간정보포털
국가중점데이터 전체 국가중점데이터가 36건 입니다. 공간융합 개방데이터(17년) - 4건 API SHP CSV API SHP CSV API SHP CSV API SHP CSV 국가공간 개방데이터(16년) - 12건 API SHP API SHP CSV API SHP CSV API SHP CSV API SHP CSV API SHP CSV API SHP CSV API SHP CSV API CSV API SHP CSV API CSV API SHP CS
openapi.nsdi.go.kr
여기서 아래의 데이터를 찾는다.

우선, 법정구역 정보부터. 어차피 작업 과정은 똑같다.

위와 같은 데이터를 찾는다. 최신의 것으로 다운받는다.
압축된 파일 중 읍면동(EMD) 파일을 QGIS에서 열면 다음과 같은 것이 나온다.

도형 내부의 중심점을 찾는 법은 여러가지가 있을텐데, 플러그인 중 RealCentroid 를 다운받아서 실행시켜보자.

이렇게 간단한게 땋! 하고 실행시키면,
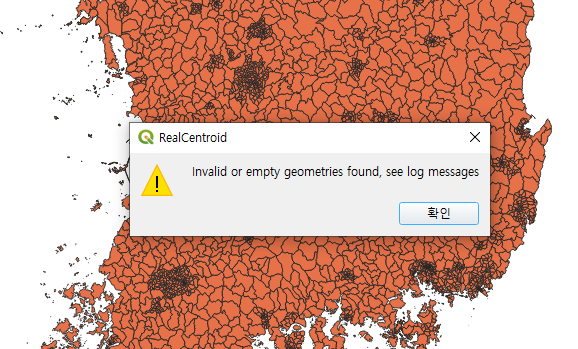
짠 하고 에러가 난다.
연결 상태나 마무리 상태가 잘못되어 있는 도형이 있어서 그렇다는데, 제발 깔끔한 도형으로 정제해서 배포해주었으면 좋겠다. 그런데 데이터 다루다 보면 완벽한 경우는 한번도 만날 수 없다.
숙명처럼 받아들이고 그냥 필요한 사람이 정제를 해야 한다.
QGIS에서 벡터 -> 도형도구 -> 무결성 검증 메뉴를 실행시키면 토폴로지 검사를 할 수 있다.

이런... 에러가 꽤 많다. 해결하는 방법에는 여러가지가 있다.
1. 토폴로지 오류를 모두 수정해서 다시 실행시킨다.
2. 예외 처리가 잘 되어 있는 다른 플러그인을 구한다.
3. GDAL이나 map shaper 등 다른 수단에서 되는지 찾아본다.
4. arcmap을 구입한다.(소문에 따르면 아크맵은 이런 예외처리가 잘 되어 있다고 한다)

그냥 여기서는 빠르게 수정하는 방법을 택한다. 어차피 토폴로지 오류가 완벽하게 수정된 도형을 만들고자 하는 것이 아니라 오류가 없는 파일로 적절하게 내부 중심점만 구하면 되기 때문에 위에 보이는 정도의 오류는 과감하게 주변 점들을 모두 삭제하는 방식으로 수정해도 전혀 문제가 없다.
그렇게 해서 real centroid 로 다시 중심점을 찾아낸다.

위의 그림과 같이 도형 내부에 중심점이 추출되었다.
point 형식의 shape 파일이 생성된다.

속성 값에 도형의 x와 y좌표를 추가한다.
필드 계산기에서 $x, $y 등으로 금새 계산할 수 있다. 정밀도가 그다지 필요 없으니 정수 형식으로 만들어도 괜찮다.
위에서 A1 필드가 법정동이다. 8자리로 되어 있는데, 뒤에 '00'을 추가하면 10자리 코드가 된다.
밑에서 설명할 법정리의 경우 마지막 두자리도 00이 아닌 다른 숫자를 사용하여 지역을 표시하고 있다.
국토부 데이터는 주로 EPSG 5174 좌표계를 이용한다. 위에 보이는 좌표값은 그 좌표계 그대로이고, 각자 UTMK 등 자신이 필요한 형식으로 좌표계를 변경하여 사용하면 된다. 좌표계에 관한 부분까지 여기서 모두 설명할 수는 없다. 구글링을 통해 찾아보면 많이 나온다.
이번에는 법정리 경계의 중심 좌표값을 추출한다. 아까 다운받은 파일에 LI 라는 이름으로 압축되어 있다.
법정동과 같은 방식으로 구하면 된다.

이제 위와 같은 테이블이 완성되었다.
PNU 코드 값에 대응하는 좌표를 찾기
이번에는 실거래가 데이터가 담고 있는 30만개 지번에 대한 좌표값을 찾아보자.
우선 전국 연속지적도에서 위와 같은 방식으로 중심점을 구한다.
물론 17개 시도의 파일을 열어서 위와 같이 작업하기는 어려우므로 좀 더 손이 덜 가는 방법들을 찾아보자. 이 부분은 지난번 다른 글의 초반부에 설명해놓았다.
공시지가 - 전국 모든 땅의 가격은 얼마나 높고 낮은가?
국토교통부 지적통계에 따르면, 2018년 말 기준으로 전국의 필지는 38,786,795개가 있다.*** 우리나라는 1990년부터 모든 토지에 대해 개별공시지가를 산정해서 발표했는데, 작년 말에 처음으로 전국 모든 토지의..
www.vw-lab.com
그래서 전국 pnu와 xy 좌표값 테이블을 완성했다면!
이제 30만개 고유 주소와 매칭만 시키면 될 줄 아셨겠지만... 그렇지 않다. 그래도 일단 매칭부터 시켜보자.
매칭시키는 방법에는 여러가지가 있다.
참조 테이블에는 PNU값, X좌표, Y좌표의 세가지 필드로 이루어진 몇천만 line이 있다.
그리고 찾아야 하는 것은 30만개 pnu값.
R이나 유사한 프로그램을 사용한다며 left_join 을 사용해보자. 해 보지는 않았는데, 몇천만 line이 조금 많긴 하지만 의외로 금방 될 수도 있다.
자바에서 HashMap이나 c++에서 std::unordered_map 과 같은 map 자료구조를 사용한다면 둘 중 어떤 것을 맵에 넣을지 잠깐 고민해봐야 한다.
개념상으로는 참조 테이블을 map에 넣고 30만개 pnu를 loop 로 돌면서 값들을 찾아오면 되는데, map에 들어가는 수가 많기 때문에 시간이 오래 걸릴 수 있다. 이럴 때는 반대로 30만개 pnu값을 map에 넣고 4천만개 pnu, x, y 값을 루프로 돌면서 매칭시키는게 메모리 측면에서 훨씬 효율적이고 빠르다.
이런 고민이 별 것 아닌 것 같지만, 정말 더 큰 자료를 다루게 될 때는 필수적이다. 엄청나게 느린 것을 빠르게 할 수도 있고, RAM의 한계로 아예 안되는 것을 되게 할 수도 있으므로.
매칭되지 않는 좌표들을 찾기

그래서 주루룩 매칭을 시키면.... 29만개 이상이 매칭되고 5563개가 남는다. 생각보다 조금 많이 남은 것 같은 느낌.
대체 남은 것들은 무엇일까?

예를 들면 위와 같은 주소다. 서초구 반포동 30-2번지
카카오 맵에서 찾아본다.

산 30-2번지가 검색되었다. 여기 아니다.
네이버 맵에서 찾아본다.
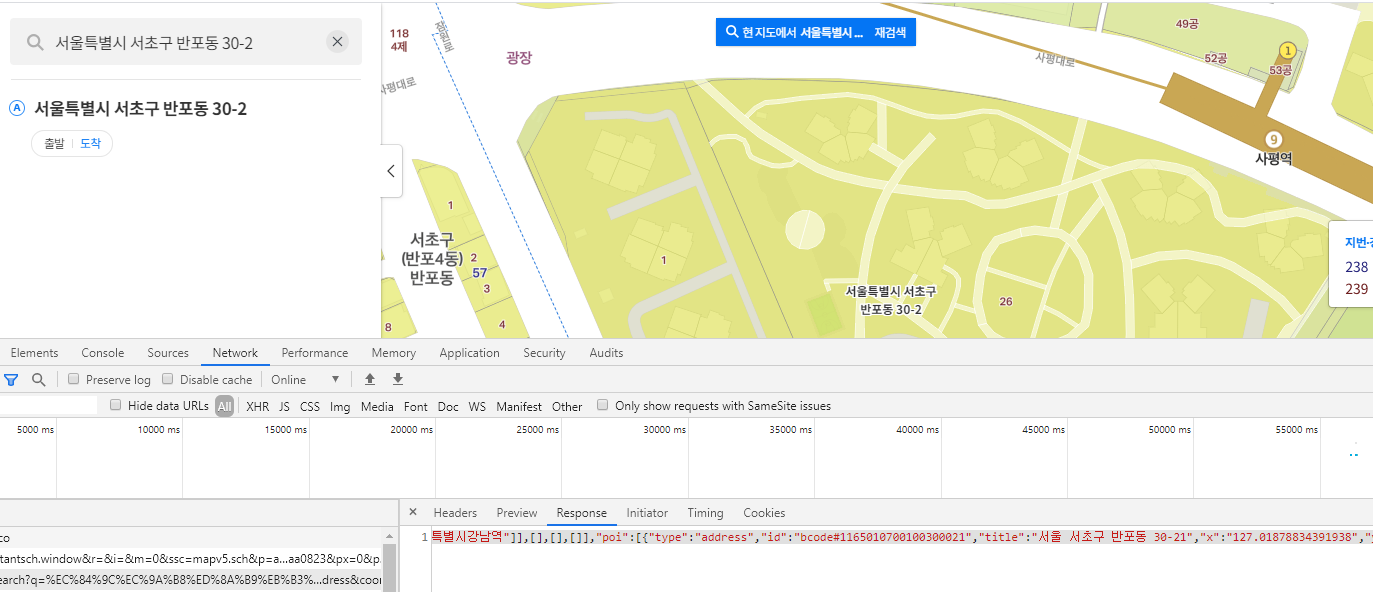
위치를 찾는 듯 하지만, 반환되는 json 정보를 열어보면 정확한 좌표값이 없고, 유사 주소로 추측하는 듯 하다.
그래도 검색 결과를 통해 앞에서 왜 매칭이 안되었는지는 알 수 있다.
바로 재건축.
2006년에는 존재하던 아파트지만, 철거된 후 다른 아파트로 재건축되면서 필지 작업을 했을테고, 그러면서 과거 지번이 사라지고 새 지번을 부여되었다. 따라서 현재의 연속지적도에는 해당 pnu가 존재하지 않는 것.
그렇다면 여기서 과거 주소를 찾는 사이트를 한번 들어가본다. 전에 봐 둔 적이 있다.
바로 LH의 씨-리얼. 과거 온나라 부동산 지도가 개편한 사이트다.
짠!

하아...
왜 만들어 놓은 것일까.
사실 되는 주소들도 있는데, 어차피 하나하나 찾아야 해서 결과가 나온다손 치더라도 크롤러를 따로 만들어야 한다.
구글링해본다.

일일이 캡쳐하기가 힘들지만, 여튼 구글 지도를 이용하면 과거주소 지오코딩이 가능하다.
국토부에서는 제대로 된 과거 주소들과 좌표값들을 DB화시켜놓았으면 좋겠다. 과거 주소들 처리할 일들이 종종 있는데, 그때마다 항상 애를 먹는다. 디테일한 해상도의 공공측량성과를 못쓰게 한 구글에서 오히려 과거 지번 주소 중심점들은 삭제하지 않고 착실하게 모아놓아서 이럴 때 많이 도움을 받는다. 참 아이러니하다.
카카오나 네이버 맵도 굳이 과거 주소들을 지울 것이 아니라 그대로 DB 안에 남겨두었으면 좋겠다. 어차피 nosql 형식이면 항목 하나 더 만들어서 '폐지'라고 이름 달아놓는게 큰 일도 아닐텐데.
그래서 구글 map API를 이용하여 WGS 84 좌표를 받았다.
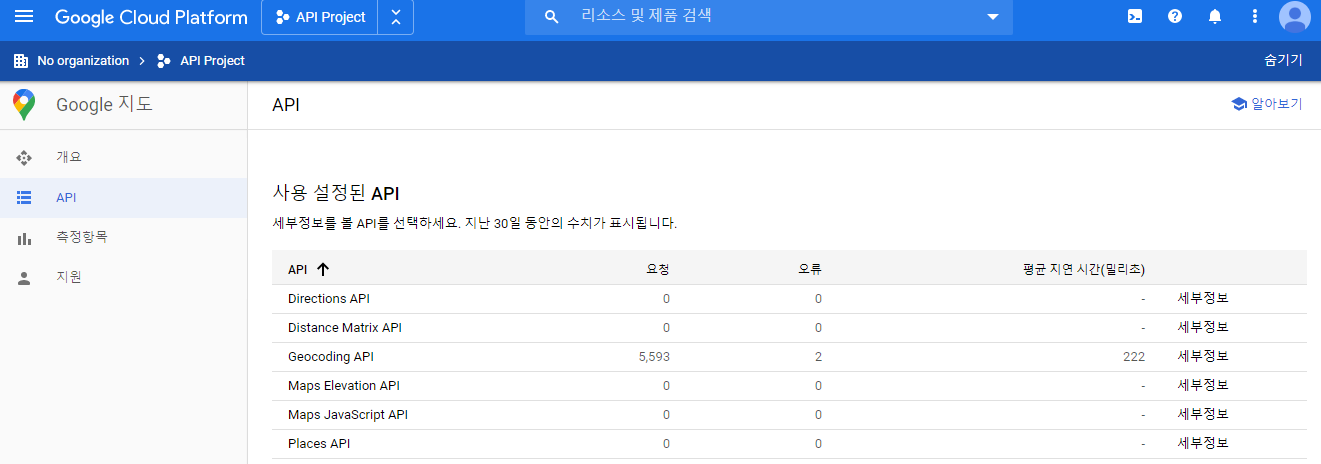
API 키를 발급받아야 하고, 언제부터인가 유료로 전환되었지만 기본적으로 무료로 이용할 수 있는 크레딧을 준다. 5563개는 충분히 된다.
그래서 5563개의 request를 보내면... 대부분 좌표를 받을 수 있다!!
여기서 잠깐 의문!
그렇다면 아예 처음부터 구글 geocoding API를 사용하면 되는 것 아닌가?
맞다. 그래도 된다.
그런데 5563개의 경우 50분 정도 걸렸다. 30만개의 경우 44시간쯤 걸리겠지. 그런데 돈 좀 쓰고, 걸어놓고 기다리면 되므로 이 방법이 나을 수도 있다. 이틀이면 알아서 되어 있는것이니까.
그런데 지오코딩하다보면 백만개 이상 해야할 경우도 있으므로 API 방식을 이용하는 것 보다, 직접 구성해서 할 수 있으면 유용할 때가 많다.
이제 아래의 목록, 즉 남은 것들 40개만 처리해주면 된다.

세종시의 경우 초기에 한차례 주소가 바뀐 것 같다. 앞에서 한차례 언급했지만, 2012년 이전 이 지역이 충청남도 소속일 때의 번지에 앞의 법정동 이름만 바뀌어서 암호가 되어버렸을 수도 있다. 그런데 구글링해보니 조금 나오기도 한다.
40개 정도면 그냥 하나하나 검색을 통해서 찾아내는 것이 정확하고 빠르다. 머리를 잘 써서 손발이 편한 경우도 있지만, 손발을 잘 써서 머리가 편한 경우도 있다. 데이터를 다루다보면 두 가지 방법을 상황에 따라 적절하게 사용해야 한다. 항상 완벽하게 할 수 없고 한정된 시간 안에서 효율적으로 빠르게 작업해야 하는 경우가 대부분이므로.
위에 번지가 0으로 들어가 있는 것들은 당연히 그냥 포기하고 법정동 중심점으로 대체시킨다.
매칭용 테이블 완성
그래서 드디어!!!!
실거래가에 존재하는 PNU 코드와 공간 좌표 매칭 테이블이 완성되었다.

위에서 3번 열이 PNU 코드, 4번 5번이 각각 x, y 좌표다.
이제 남은 일은 자잘한 작업들이다.
원본 실거래가 파일에 존재하는 법정동주소와 본번 부번을 이용해서 PNU 코드를 만든다.
그리고 위에서 만든 매칭용 테이블을 이용해서 좌표값을 넣어준다.
각 파일은 많아야 1000만 line 수준이므로 left join 이나 그와 유사한 코드를 작성하여 완성할 수 있으리라 생각한다.
원천 데이터에 pnu와 x,y 좌표 부여 - 끝인 것 같으나 끝이 아닌 단계.

앞에서 만든 매칭 테이블로 원본 파일 앞 쪽에 pnu코드와 좌표를 추가해서 완성했다.
그런데 좌표값들이 약간 이상하다고 생각할 것 같다.
확대해볼까.
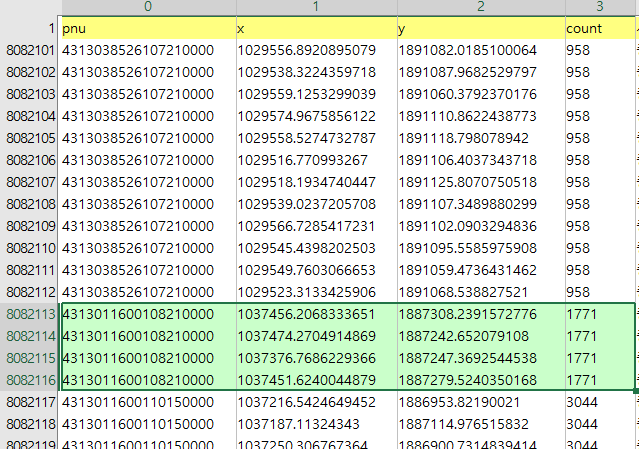
같은 pnu 값인데 좌표값이 모두 다르다. 일부러 그렇게 했다.
이제부터는 좌표값을 흔들어서 분산시키는 방법에 대해 설명해보겠다.
왜 좌표값을 분산시키는가?
그냥 한 주소에 같은 좌표를 매칭시킨 후 실거래가를 지도에 뿌려보면 아래와 같은 그림이 나온다.

얼핏 보면 별 문제 없는 것 같지만... 한번 확대해보자.

앞의 방식으로는 당연히 한 아파트에 하나의 좌표만 부여된다. 그러므로 한 아파트의 무수히 많은 거래가 모두 한 점에 찍히게 된다.
이래서는 알아보기 쉬운 그림이 나오지 않는다. 시각화란 본래 데이터를 한 눈에 쉽게 파악하기 위함인데, 서로 다른 정보들이 한 좌표에 표현된다면 드러낼 수 없는 것들이 너무 많아지기 때문이다.
아마도 상점 데이터들을 시각화 해 본 사람들이라면 한 번 쯤 고민해 본 문제일 것 같다. 한 상가 안에 음식점이 10개 이상 있는데 모두 한 점에 찍혀버려서 도대체 구분할 수가 없었던 경험이 있었을 것 같다.
그래서 좌표를 흔든다.
점들이 서로 겹치지 않도록 주변으로 분산시키는 방식이다.
그렇다면 '어떻게' 분산시킬까?
가장 정확하게 해보자면 분산시키더라도 해당 지번 경계 안에서만 놓이도록 랜덤 발생과 경계 검사를 반복적으로 해주는 방법도 있겠지만 거기까지는 약간 번거롭기 때문에, 이번에는 단순한 방법을 택하기로 했다.
가장 쉽게 하려면, 그냥 모든 좌표들을 위에서 검출된 중심점 주변으로 적절하게 난수를 발생시켜 더하고 빼주는 방법을 사용하면 된다.
그런데 실거래가 많이 집중된 주소와 그렇지 않은 주소들을 이렇게 동일하게 처리해주면 오히려 식별이 어렵게 된다.
변위를 작게 흔들면 아주 많은 점들은 그래도 많이 겹치고, 크게 흔들면 한 두개 짜리 점들도 엉뚱한 곳으로 가 버린다.
두 번째 방식은 해당 좌표가 등장한 개수를 센 후 그 개수에 비례하도록 난수의 변위를 부여하는 방식이다.

우선 위의 그림처럼 11개의 데이터셋들 전체에서 고유한 pnu 값들이 등장한 횟수를 센다.
보시다시피 1106개와 1~2개의 빈도가 같은 데이터 셋 안에 공존한다.
이 때 x, y좌표를 각각 ( rand( ) -0.5 ) * count 로 계산해주면 각각의 좌표가 사각형 안에서 랜덤하게 발생하게 된다. 빈도 수(count)를 곱해주었으므로 거래량이 많은 주소는 더 큰 사각형을 그리고, 작은 주소는 원래 중심 좌표 주변에 찍히게 된다.
여기서는 비슷하지만 다른 방식으로 좌표값을 만들었다. x,y 좌표가 아니라 극좌표계 형식을 이용하는 방법이다.

위 처럼 간단한 코드로 계산할 수 있다. 마지막에 나눈 20.0 값은 약간의 시행착오를 통해 적절한 크기로 분산 되도록 부여한 값이다.
그렇게 하여 실거래가를 QGIS에서 간단히 다시 뿌려보면 아래와 같은 그림이 된다.

거래량이 많으면 넓게 퍼지고, 적으면 작게 퍼진다.
그러고 보니 퍼진 원의 크기가 총 거래량에 대한 지표가 되어 하나의 그림으로 또 다른 정보도 표현할 수 있게 되었다.
그리고 위에서 설정한 극 좌표의 난수발생 특성상 원 안에 고르게 퍼지는 것이 아니라 중심 부분에 좀 더 모이게 되는데, 오히려 이 방식이 본래 중심점을 잘 표현해주는 것 같아 그대로 사용하기로 했다.
여기까지 좌표 부여 설명 끝.
월세를 전세가로 일괄적으로 환산시키기
기왕 한 김에 한 가지만 덧붙여보자.
좌표는 아니고, 전월세가 즉 전세와 월세가 섞여 있는 데이터를 모두 전세가로 전환시켜서 하나의 척도로 만드는 방법이다.
전월세 전환율을 적용시키면 되는데, 데이터만 찾으면 그다지 어렵지 않다.
우선 아파트, 연립주택, 단독다가구의 지역별 전월세 전환율은 국가통계포털에서 어렵지 않게 찾을 수 있다.

위의 그림처럼 생겼다. 세종시같은 경우 2012년 이전에는 없으므로 충청남도의 값을 복사해서 (혹시 모르니) 빈칸을 채워둔다.
오피스텔은 국가통계포털과 감정원 데이터는 2018년부터 있으므로 KB주택가격동향 데이터를 사용했다.
https://onland.kbstar.com/quics?page=C059744
월간 KB주택가격동향 ( KB부동산(LiivON) | 뉴스·자료실 | 통계/리포트 | 월간 KB주택가격동향 )
onland.kbstar.com
오피스텔의 경우 2010년 7월부터 있는데, 서울, 경기, 인천의 데이터만 있다. 사실 전월세 실거래가 데이터가 모두 있다면 지역별로 전월세 전환율을 만들 수 있다. 일단 대략 보고자 하는 것이니 최대한 있는 자료를 활용하자는 차원에서 서울 경기 인천 이외의 지역은 인천의 값을 적용시켰다.(정말 중요할 경우 이렇게 하면 안된다)
그리고 한가지. 전월세 전환율은 어쩔 수 없이 한 가지 척도로 변환하여 비교하기 위해서만 부득이하게 적용시켜야 한다. 왜냐하면 월세에 들어가는 사람들이나 월세를 놓는 사람들이나 다들 시장상황과 개인사정에 따라 각자 판단하여 결정한 것이기 때문이다. 따라서 일괄적으로 전환시키면 데이터가 담고 있는 특정한 부분을 놓칠 수 있다. 월세를 사는 사람은 목돈이 없기 때문일 수도 있고, 월세를 놓는 사람들도 전세금의 재투자나 여러가지 수익을 고려하기 때문이다.
간단한 수식이지만 전월세 전환율은 다음과 같이 전세금으로 계산할 수 있다.
전세로 전환된 금액 = (12*월세 / (전월세 전환율/ 100)) + 보증금;
쓰다보니 꽤 길어진 글을 이만 마무리하기로 한다.
앞에서도 설명했지만,
이 데이터를 처리하기 위해서는 어떤 파이썬이든 R이든 자바든 파일 입출력과 문자열 처리 정도는 할 수 있어야 한다.
세세한 디테일은 미처 설명하지 못했으므로, 혹시 설명이 부족한 부분이 있다면 각자 익숙한 언어와 도구에서 검색하기를 권한다.
기본적인 질문에는 하나하나 답변을 달 수 없는 점에 대해 미리 양해를 구합니다.
원본 데이터와 좌표 등등 처리된 데이터는 앞에서 소개한 깃헙에 올려놓았다.
https://github.com/vuski/RealEstateTransactionKorea
vuski/RealEstateTransactionKorea
부동산 실거래가. Contribute to vuski/RealEstateTransactionKorea development by creating an account on GitHub.
github.com
'Function' 카테고리의 다른 글
| Nvidia Mesh Shader 코드를 작성해보자 (2) | 2020.05.17 |
|---|---|
| 데이터로서의 이미지 : 수백만개 선들의 적층과 재분해 (4) | 2020.04.25 |
| 공시지가 - 전국 모든 땅의 가격은 얼마나 높고 낮은가? (1) | 2020.03.02 |
| 텍스트 빈도와 네트워크 인터랙티브 시각화 (6) | 2019.08.31 |
| 많은 양의 개체들을 시각화하는 방법, 그리고 전국의 모든 건물 (7) | 2019.03.27 |



