
얼마 전 Unreal Engine 5의 데모가 공개되면서 엄청난 디테일의 표현을 가능하게 한 Nvidia 의 Mesh Shader 방식이 화제가 되었다.
A first look at Unreal Engine 5
Get a glimpse of new and improved real-time rendering features currently in development.
www.unrealengine.com
이 글에서는 Mesh Shader 를 직접 구성해보는 방법에 대해 설명한다. OpenGL 기준이며, 최소한 glDrawArrays 와 같은 드로우 명령을 통해 vertex shader - geometry shader - fragment shader 를 통과시키면서 개체들을 그려본 경험이 있는 사람들을 대상으로 작성했다. 권장하자면, compute shader 를 사용해보았으면 더 좋다.
이제까지 VWL 홈페이지에 올린 글들은 코딩을 할 수 없더라도 어느정도 소통이 될만한 내용들이었다. 그런데 이번에는 처음으로 OpenGL 코드 작성이 가능한 사람들을 대상으로 써봤다.
직접 코딩을 해 본 사람들이 아니라면, 개념 정도를 비교하는 글의 전반부 정도는 메쉬 셰이더에 대한 어느 정도 궁금증을 해소하는데 도움이 될 것 같다.
글의 중간중간에 인용한 코드는 글의 마지막에 전체를 수록해놓았다.
들어가며.
메쉬 셰이더를 통해 우리나라 전국의 모든 건물과 도로 등을 그려보는 시도를 한지도 1년이 넘었다. 아래 글의 후반부에 그에 대한 설명이 있다.
많은 양의 개체들을 시각화하는 방법, 그리고 전국의 모든 건물
글 : 김승범 공간 데이터를 시각화하다 보면 종종 양적인 문제에 맞닥뜨린다. 특수효과로 화면을 뭉개기보다는 좌표점을 입력하여 정직하고 명료하게 표현하는 일이 대부분이다. 간혹 '어선 경�
www.vw-lab.com
사실 처음에 메쉬 셰이더로 그려보려고 엔비디아의 소개 글을 몇 번을 읽었지만, 정작 막상 코드를 작성하려면 무엇을 어떻게 써야 할지 전혀 알 수가 없었다. 그래서 엔비디아가 깃허브에 올려놓은 아래의 코드를 찾았는데, 너무 많은 내용이 섞여 있어서 정작 무엇이 핵심인지 알기가 어려웠다.
nvpro-samples/gl_vk_meshlet_cadscene
This OpenGL/Vulkan sample illustrates the use of "mesh shaders" for rendering CAD models. - nvpro-samples/gl_vk_meshlet_cadscene
github.com
그래서 하나를 더 찾았는데, 이 두가지를 비교해보면서 대략적으로 감을 잡을 수 있었다.
jdupuy/opengl-framework
Cross-platform OpenGL demos. Contribute to jdupuy/opengl-framework development by creating an account on GitHub.
github.com
맨바닥에서 메쉬 셰이더로 무언가를 그리기까지 꼬박 일주일 같은 시간 정도가 아니라 정말 많은 시간을 썼다. 문법과 규칙에 대한 자세한 설명이 없다 보니, 시도해보고 안되면 다르게 다시 시도해보고 하는 방식으로 찾아나갔던 것 같다.
그래도 결과적으로는 놀라운 성능 향상을 체감했다.
그런데 사실 1년동안 메쉬 셰이더로 다른 코드를 짠 적이 없다보니, 이 글을 쓰려고 다시 펼쳐 보았을 때 꽤 많은 부분이 머릿속에 남아 있지 않았다. 어떤 점이 헷갈렸는지는 기억이 나는데, 정작 그래서 그게 무엇이었는지 적어놓지 않았던 것. 항상 느끼는 것이지만, 영화 <메멘토>의 주인공이 되었다는 마음가짐으로 보다 상세히 주석을 써 놓으리라 생각해본다.
그럼 글을 시작해볼까. 개념부터 살짝 훑어보자.
Mesh Shader의 개념과 장점
Nvidia 의 Mesh Shader를 이용하면 기존의 고정된 파이프라인에서 벗어나 조금 더 동적으로 파이프라인의 개수를 제어할 수 있다. 정해진 모든 삼각형들을 항상 모두 그려야 할 경우에는 아마도 기존의 고정 파이프라인이 더 빠를 것 같다.
단, 화면의 시점을 움직일 때 화면 경계에서 벗어난 부분을 제외시키거나, 거리에 따라서 LOD를 다르게 생성하는 등 상황에 따라 그리게 될 삼각형들을 동적으로 제어하고 싶다면 Mesh Shader는 좋은 대안이 될 수 있다.
단, 신경써야 할 것 들이 많기 때문에, 굳이 기존의 단순하게 구성할 수 있는 고정 파이프라인을 항상 대체할 필요는 없을 것 같다.
다음의 글에 메쉬 셰이더의 여러가지 개념들이 잘 설명되어 있다.
https://devblogs.nvidia.com/introduction-turing-mesh-shaders/
Introduction to Turing Mesh Shaders | NVIDIA Developer Blog
Turing introduces a new programmable geometric shading pipeline, mesh shaders,, enabling threads to cooperatively generate compact meshes on the chip.
devblogs.nvidia.com
OpenGL의 일반적인 파이프라인은 다음의 세 단계를 거친다.
vertex shader → geometry shader → fragment shader
두 번째 단계인 지오메트리 셰이더는 생략 가능하지만 꽤 자주 사용되는편이다.
Nvidia 의 Mesh Shader는 다음의 세 단계를 거친다.
task shader → mesh shader → fragment shader
fragment shader는 기존과 같다고 보면 된다.
fragment shader를 생략하고 파이프라인을 단순하게 도식화해보면 아래와 같다.

기존의 전통적인 파이프라인에서 vram으로부터 읽은 데이터가 일단 파이프라인 안으로 들어왔을 때, 그 중 어떤 데이터들을 조건문을 통해 선택적으로 그리지 않으려면 두 가지 방법이 있다. 하나는 geometry shader에서 EndPrimitive 함수를 호출하지 않는 방법. 다른 하나는 fragment shader에서 discard 명령어로 해당 pixel을 무효화시켜버리는 방식이다. 그래서 위의 그림에서 빨간 점선(파이프라인)의 마지막에 x(취소)로 표현했다.
두 방식 모두 파이프라인의 후반부에서 취소가 이루어지기 때문에 대부분의 파이프라인을 거치면서 자원을 소모하게 된다. 그에 비해 Mesh Shader 방식은 task shader와 mesh shader로 이름붙여진 두 가지 단계들을 거치게 되는데, 두 단계에서 모두 취소할 수 있다.
그리고 기존의 방식이 모든 데이터를 파이프라인 안으로 밀어넣는 방식이라면, 메쉬 셰이더 방식은 데이터들을 선택적으로 읽어올 수 있다. 그러므로 공간적으로 인접한 점들을 100개씩 묶어서 데이터를 준비했다면, 그 중 1개의 점만 화면 안에 들어오는지 task shader에서 검사하고, 화면 경계에서 적당히 버퍼를 둔 만큼을 벗어난다면 그 그룹은 mesh shader로 전송하지 않으면 된다. 그러므로 모든 점들을 검사하는데 비하여 이론적으로는 1/100의 시간만 사용할 수 있다. 그래서 위 그림의 아래 부분에서는 파이프라인 중간에 x를 표시했다.
다시 위의 그림과 아래 그림을 비교해보면 마지막에는 똑같이 3개의 점이 fragment shader로 넘어가는데, 메쉬 셰이더에서는 짧은 점선 5개 분량의 파이프라인 자원이 소모된다면, 위에서는 12개 분량의 파이프라인 자원이 소모된다. )물론 정확히 5:12의 비율이라고 말할 수는 없다.)
그렇다면 메쉬 셰이더는 데이터의 효율적인 취사선택이 유일한 장점일까? 그렇지 않다.
비슷한 그림을 하나 더 그려봤다. 아래 그림을 보자.

엔비디아의 메쉬 셰이더 설명을 보면 'Meshlet'이라는 용어가 등장하는데, 인접한 점들을 그룹으로 묶어서 다루는 개념이다. 앞서 설명한 예가 이 Meshlet 들을 task shader와 같이 파이프라인의 첫단계에서 취사선택할 수 있다는 부분이었다.
이제 위 그림의 아래쪽에 있는 vertex C와 vertex D를 비교해보자.
예를 들어 입력된 한 점을 바탕으로 조건에 따라 삼각형이나 오각형을 그린다고 생각해보자.
삼각형은 정점 3개를 EmitVertex() 하고 EndPrimitive() 하면 된다.
오각형은 정점 5개를 특정한 순서로 EmitVertex() 한 후 EndPrimitive() 하면 된다. triangle_strip 으로 만들게 된다.
기존의 파이프라인에서는 geometry shader가 이 역할을 담당했다. 그런데 이런 작업이 병렬적으로 이루어지므로 3개를 처리한 코어가 옆동네에서 5개를 처리할 때까지 2개의 시간만큼 대기하게 된다. 그런데 메쉬 셰이더 방식에서는 이 대기 시간을 없애고 그 시간에 옆 동네에서 아직 못한 일들을 맡을 수 있도록 설계했다는 것 같다.
엔비디아 devblog에서 아래의 표로 설명하고 있다.
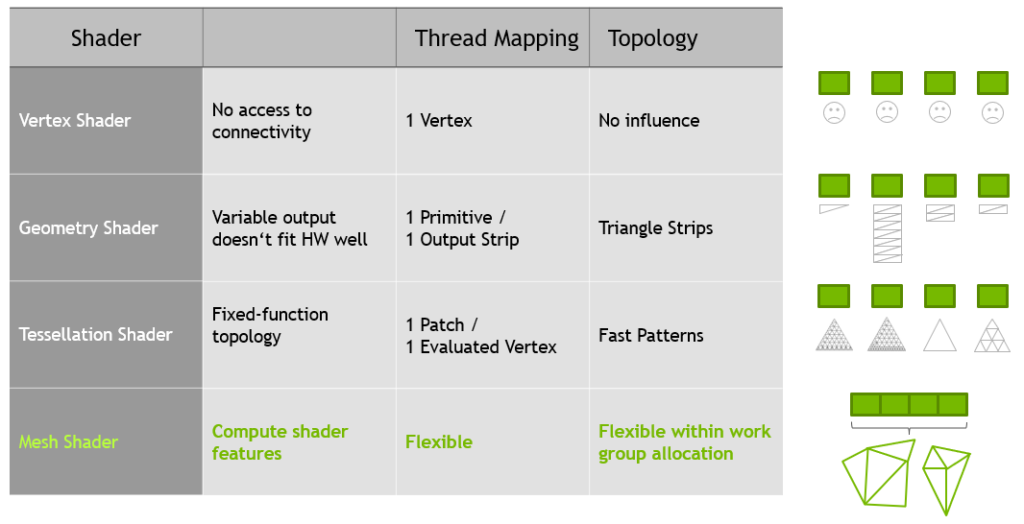
geometry shader의 설명을 보면, output의 수가 유동적으로 변할 수 있지만, 하드웨어를 충분히 잘 사용하지 못한다고 말한다. 앞서 설명한 것처럼 가장 많이 생성하는 코어의 시간에 맞추어지기 때문에 그렇다.
mesh shader의 설명을 보면, Thread Mapping이 Flexible이라고 표현되어 있다. 통상적인 경우 한 그룹안에서 32개 쓰레드가 병렬적으로 같이 움직이는데, geometry shader는 한 쓰레드가 다른 31개의 쓰레드와 관계없이 독립적으로 움직이는데 반해 mesh shader는 같은 워크그룹으로 할당된 32개의 쓰레드가 서로 협동해서 삼각형들을 만든다고 설명되어 있다.
실제로 mesh shader를 작성하다 보면 한 쓰레드 기준으로 볼 때 정점을 0,1,2 이렇게 3개만 방출하는데 다른 쓰레드에서 방출하게 될 10번 vertex를 인덱스로 호출할 수 있다. 어느 지점에서 쓰레드를 동기화 시키는 barrier() 류의 명령어 없이 그것이 가능하려면 엔비디아의 설명대로 쓰레드 협동 모델이 작동해야 한다. 이 부분은 나중에 코드 작성 부분에서 다시 설명할 예정이다.
이러한 특징은 동적 LOD 생성에 아주 적합할 것 같다.
예를 들어 한 프레임에 복잡한 지형을 그려야 하는데, 어떤 부분은 시야 가까이에 있어 자세히 그려야 하고, 어떤 부분은 꽤 멀리 있어 적절히 생략하면서 그려야 하는 상황을 생각해보자.
기존의 방식으로는 지형 전체에 대해 같은 밀도의 데이터가 파이프라인에 투입되므로, 제어가 까다롭다. 가장 자세할 때 0번과 1번, 1번과 2번 점들을 이어 물체를 그린다면, 조금 덜 자세할 때 1번은 건너뛰고 0번과 2번을 이어 물체를 그릴 수 있도록 데이터를 준비해놓았다 하더라도 점들이 순차적으로 투입되는 상황에서는 건너 뛸 방법이 애매하다.
glDrawElement 방식으로 그리면 인덱스를 사용하므로 데이터들을 적절히 건너뛸 수는 있는데, 어차피 하나의 인덱스 그룹만 바인딩되어 인덱스 역시 순차적으로 밀어넣기 때문에 어떻게 할 수 있을지 잘 모르겠다. 만약 화면 전체적으로 LOD를 다운시킨다면 아예 glDrawElement 를 할 때 LOD가 다르게 구성되어 있는 인덱스 버퍼를 바인딩하면 되는데, 한 프레임 안에서 먼 곳은 다운시키고 가까운 곳은 자세히 그려야 하는 상황에는 쉽게 대응하기 어려울 것 같다.
그런데 메쉬 셰이더라면 어차피 인덱스로 데이터를 끌어오는 방식이므로 그냥 0번과 2번, 4번, 6번을 불러들여서 그림을 그리면 된다. 물론 그렇게 이어도 개체가 잘 생성되도록 전처리를 해놓았다는 가정하에. (반복적 패치가 아닐 경우 실제로 이런 방식으로 하는지는 잘 모르겠다. 그리고 수학적으로도 점들의 개수를 일정하게 건너뛰면서 그렸을 때 메쉬렛 상호간에 정점이 잘 맞는 개체를 완결시킬수 있는지는 잘 모르겠다)
혹은, 여러가지 LOD 인덱스들을 바인딩 시켜놓고, 셰이더 안의 조건문들을 통과시키면서 먼 개체는 낮은 LOD의 인덱스들을 통해 그리고 가까운 개체는 높은 LOD의 인덱스들을 통해 그릴 수 있게 된다. 대부분의 메쉬렛 인덱스는 1byte를 할당하기 때문에 LOD에 따른 인덱스 여러벌이 그렇게 부담스러운 용량은 아닐 것 같다.
물론, 기존에 방식에서도 불가능한 것은 아니지만 컴퓨트 셰이더를 통해 전처리를 해야 한다. 최소한 데이터들을 한바퀴 읽어서 복사하는 작업을 해야 한다는 말이다. 혹은 LOD를 조정할 때 테셀레이션 셰이더를 사용할 수도 있는데, 테셀레이션은 '분할'에 가까우므로 반복적 패치 형식의 물체에 적용하는 것은 가능하지만 자유로운 형상을 그리기는 어렵다. 적용이 다소 제한적일 것이라 생각된다.
draw call 이전에 화면 바깥의 물체들을 제거(frustum culling)하거나 특정 조건의 개체들을 제외하고 싶다면, 두 가지 방식 정도를 생각해 볼 수 있겠다.
우선 meshlet 처럼 개체들을 인접한 그룹으로 분할해놓았으며, 각각의 그룹 내에서 triangle_strip 방식으로 그릴 수 있는 위상으로 구성된 상태라고 가정해보자. 이 때는 아마도 glMultiDrawArraysIndirect 방식으로 많이 그릴 텐데, indirect 버퍼만 훑어가면서 각 그룹의 first vertex 만 검사하면서 빠르게 데이터를 재구성할 수 있다.
한 가지 방식은 vram 이 아닌 ram 상에 vertex와 indirect 데이터들을 별도로 적재해놓고, cpu에서 indirect 그룹의 한 정점들만 읽어들이면서 조건문에 통과시켜보는거다. 일반적으로 vertex 데이터에 비해 indirect 데이터의 양은 매우 적으므로 훑어야 할 양이 많지 않아 아주 빠르게 처리가 가능하다. 대신 indirect 버퍼를 glBufferSubData 방식으로 업데이터 해주어야 한다. ram에서 vram으로의 복사는 어떤 방식으로든 한번은 이루어져야 한다. (glMapBuffer 를 통해서 cpu 에서 곧바로 vram 에 엑세스 할 수도 있지만 실제로 이 방식으로 루프를 돌려보면 엄청나게 느리다)
만약 통과 조건을 계산하는 과정이 복잡하다면 compute shader를 통해 계산가능하다. 이 때는 굳이 ram을 거칠필요 없이 vram에서 vram으로 곧바로 복사 재구성이 가능하지만, 새로운 indirect 버퍼에 데이터를 순차적으로 기록하기 위해 atomicCounter를 사용해야 한다. 어토믹 카운터는 병렬 쓰레드들이 어느 순간에는 한 줄로 서서 기다려야 하기 때문에 약간의 핸디캡이 있다. 물론 실행시켜보면 예상보다는 아주 빠르게 데이터를 기록하기는 한다.
아마도 기존의 파이프라인을 사용했던 게임 개발자들도 다양한 방식으로 최적화를 하고 있을테고, 나는 그에 대한 경험은 없으니 그저 상상과 추측으로 썼을 뿐이다. 여하튼간에 메쉬 셰이더는 그 모든 작업들을 편리하고, 하드웨어의 자원을 효율적으로 사용할 수 있도록 해 주는 방식이다.
최근에 발표했으며, Mesh Shader 방식을 사용했다고 하는 언리얼 엔진 5의 데모를 보고 사람들이 감탄하는 것을 보면, 아마도 기존 방식으로는 어느 정도의 한계가 있었던 것 같다.
자, 그럼 개념 설명은 여기까지 하고, 이제 본격적으로 코드 작성을 시작해보자.
준비물 : Turing 아키텍쳐 카드와 glad.c
우선 mesh shader를 지원하는 Nvidia 그래픽카드가 필요하다.
RTX 시리즈나 GTX 1660 와 같이 Mesh Shader를 지원하는 그래픽카드가 별도로 있다. Turing architecture를 사용한 칩에서 작동하는 것 같다.
그리고 코드를 작성해야 하는데.... 사실 처음에 코드를 작성해보려고 했을 때 여기서부터 막혔다.
나는 기존에 윈도우 환경에서 glew 라이브러리를 사용하고 있었는데, 메쉬 셰이더 드로우콜에 해당하는 glDrawMeshTasksNV 같은 명령어를 지원하지 않았다. glew의 업데이트는 매우 느린 듯했다.
그래서 찾아보니 glad가 있었다. 최신 명령어들도 지원했기 때문에 깔끔하게 해결되었다.
다시 설명하자면, 일단 RTX 그래픽카드를 꽂은 후 최신 드라이버를 설치하는 순간 glDrawMeshTasksNV 명령어에 필요한 라이브러리들은 이미 컴퓨터에 설치되어 있다고 보면 된다. glad는 .c 파일과 .h 파일 두개로 구성된다. 내용을 들여다보면 glDrawMeshTasksNV 와 같은 함수를 좀 더 가독성이 낮은 함수 이름들로 바꿔서 드라이버에 포함된 라이브러리들을 호출하는 것 같다. glew를 사용할 때는 dll도 설치했는데, 왜 glad는 dll이 필요없는지 모르겠지만, 여튼 구동이 아주 잘 된다.
단, glad는 사이트에서 다운받을 때 버젼을 직접 명시하고 Extension들을 직접 포함시켜줘야 하는데, 아주 어렵지는 않다. 아래의 링크를 클릭하면, 당시에 포함시킨 라이브러리 및 같은 옵션으로 파일을 받을 수 있다.
https://glad.dav1d.de/#profile=compatibility&language=c&specification=gl&loader=on&api=gl=4.6&extensions=GL_ARB_shader_draw_parameters&extensions=GL_ARB_shading_language_include&extensions=GL_NV_bindless_multi_draw_indirect&extensions=GL_NV_bindless_multi_draw_indirect_count&extensions=GL_NV_bindless_texture&extensions=GL_NV_gpu_shader5&extensions=GL_NV_mesh_shader&extensions=GL_NV_shader_thread_group&extensions=GL_NV_shader_thread_shuffle&extensions=GL_NV_stereo_view_rendering&extensions=GL_NV_viewport_array2
gl Version 1.0Version 1.1Version 1.2Version 1.3Version 1.4Version 1.5Version 2.0Version 2.1Version 3.0Version 3.1Version 3.2Version 3.3Version 4.0Version 4.1Version 4.2Version 4.3Version 4.4Version 4.5Version 4.6None
glad.dav1d.de
generate 버튼을 눌러 다운받으면 된다.
자신이 구성한 항목들은 get 방식의 웹사이트 request로 구성되어 glad.c 파일 안에 텍스트로 포함되어 있다. 이 링크로 다시 옵션을 재현하여 동일하게 다운받을 수 있다. 위의 링크고 내가 가지고 있는 glad.c 파일에서 복사한 것이다.
freeglut 도 되는지는 모르겠으나, 일단 glfw 환경에서 작업했다. 만약 freeglut를 사용하는 사람이 있다면, 향후 약간의 확장성을 위해서 freeglut보다는 glfw를 권장한다. freeglut는 화면을 구성할 때도 가로세로 16픽셀씩 모자라기도 하고(버그), ImGui 등을 사용하려 할 때도 문제가 생기기 때문이다.
C++에서 draw call 보내기 전까지
task shader와 mesh shader 코드를 컴파일 하는 과정은 기존 셰이더들과 같다. glCreateShader 할 때만 아래처럼 하면 된다.
|
1
2
3
|
unsigned int shaderTask = glCreateShader(GL_TASK_SHADER_NV);
unsigned int shaderMesh = glCreateShader(GL_MESH_SHADER_NV);
unsigned int shaderFrag = glCreateShader(GL_FRAGMENT_SHADER);
|
cs |
일련의 셰이더 컴파일 과정에서 딱 한 단계, glCreateShader할 때만 다른 상수값을 넘겨주면 된다. 기존의 GL_FRAGMENT_SHADER와 같은 정의어 대신 GL_TASK_SHADER_NV 와 GL_MESH_SHADER_NV를 사용해서 각각 컴파일하면 된다. 다른 점은 그것뿐이다.
드로우 콜은 다음과 같이 보낸다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
glUseProgram(soRiver);
//uniform 변수 보내기
glUniformMatrix4fv(modelview_shaderRiver, 1, GL_FALSE, glm::value_ptr(modelviewM));
glUniformMatrix4fv(projection_shaderRiver, 1, GL_FALSE, glm::value_ptr(projectionM));
glUniformMatrix4fv(pmv_shaderRiver, 1, GL_FALSE, glm::value_ptr(pmvM));
glUniform4fv(frustum_shaderRiver, 6, glm::value_ptr(frustumPlanes[0]));
glUniform1f(scaleZ_shaderRiver, scaleZ);
//필요한 버퍼(데이터)들을 바인딩하기
glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 0, riverBO.ubo);
glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 1, riverBO.mshltVertex);
glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 2, riverBO.idbo);
glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 3, riverBO.mshlt);
glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 4, riverBO.mshltSub);
glBindBufferBase(GL_ATOMIC_COUNTER_BUFFER, 5, atomic_counter2_buffer);
glDrawMeshTasksNV(0, (riverBO.numObj + 31) / 32);
|
cs |
기존 파이프라인 방식과 비교했을 때 다른 점은, vertexArray를 바인딩하지 않는다는 점이다. 앞서 말한것처럼 모든 점들을 순차적으로 보내는 것이 아니므로 vertexArray 는 없으며, 대산 shader storage buffer 나 uniform buffer 등을 바인딩하여 사용한다. 위의 예에서는 riverBO.mshltVertex 가 버텍스 버퍼 오브젝트고, 나머지들이 보조적인 정보들이다.
C++ 코드에서 메쉬 셰이더 파이프라인은 다음과 같은 드로우 명령으로 호출한다.
glDrawMeshTasksNV(0,4);
두 번째 변수로 workgroup의 수를 정해준다. 위의 경우에는 총 4개의 workgroup이 생성 후 실행된다.
첫 번째 변수는 4개의 workgroup 중 첫 번째 workgroup의 id가 된다. 여기서 첫 workgroup의 id는 0이다. 셰이더 안에서 data에 엑세스 할 때 이 workgroup id를 활용하게 되므로 첫 번째 변수를 잘 이용할 수도 있다.
예를 들어 위에서는 workgroup id 가 0,1,2,3 의 4개가 생성되고 변수 값을 (0,4) 이 아닌 (3,4)로 쓴다면, 셰이더 내부에서 받아오는 workgroup id 가 3,4,5,6 까지의 4개가 생성된다.
앞의 예에서 (riverBO.numObj + 31)/32 로 워크그룹 수를 정해준 까닭은, 아래처럼 내부에서 워크그룹 사이즈를 32로 맞추어준 것과 관련이 있다. Compute Shader를 사용해본 사람이라면 쉽게 이해할 것이다. 예를 들어 그려야 하는 물체가 100개라면, 밖에서 (100 + 31) / 32 = 4.09 이므로 4개의 워크 그룹을 호출하고, 셰이더 내부에서는 4개 워크 그룹 각각에서 100개의 물체들을 각각의 워크그룹이 32, 32, 32, 4 개씩 나누어 실행도록 코드를 구성해주면 된다.
기본적인 task shader
그럼 일단 기본적인 task shader를 구성해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
#version 460 core
#extension GL_NV_mesh_shader : enable
#define WARP_SIZE 32
#define GROUP_SIZE WARP_SIZE
layout(local_size_x = GROUP_SIZE) in;
uint baseID = gl_WorkGroupID.x *GROUP_SIZE;
uint laneID = gl_LocalInvocationID.x;
//taskNV로 항상 output을 만든다. 이것은 mesh shader에서 접근 가능하다.
//이 데이터는 워크 그룹 안에서 공유한다. 그러므로 배열로 만들어주어야 한다.
taskNV out Patch{
uint baseID;
uvec3 workGroupSize;
uint laneID[GROUP_SIZE];
uint localInvocationIdx[GROUP_SIZE];
} taskOut; //여기서 지정하는 수는 mesh shader와 반드시 맞아야 한다.
void main()
{
if (laneID==0) {
taskOut.baseID = baseID;
taskOut.workGroupSize = gl_WorkGroupSize;
}
taskOut.laneID[laneID] = laneID;
taskOut.localInvocationIdx[laneID] = gl_LocalInvocationIndex;
gl_TaskCountNV = 1; //워크그룹당 할당되는 수임
}
|
cs |
우선 glsl 버젼은 460으로 셋팅하고, GL_NV_mesh_shader 라는 이름의 extension 을 enable시켜준다. 가장 기본이다.
앞에서 이어, 그려야 할 물체가 100개라고 가정해보자. 그리고 셰이더 외부에서 glDrawMeshTasksNV(0,4) 로 드로우콜을 보내서 0,1,2,3 의 gl_WorkGroupID.x 가 생성된 상황이다.
한 그룹을 구성하는 하위 레벨은 다음과 같이 32개로 구성해주는 것이 좋다. 그래야 병렬 쓰레드 숫자인 32와 일치하기 때문이다. 그리고 하드웨어의 물리적 한계와 관련있기 때문에 32가 최대값이다.
layout(local_size_x = 32) in;
이렇게 4개의 워크그룹을 발생시키고, 각 그룹의 하위 레벨을 32개 단위로 정의하면, 다음과 같은 실행 단위가 만들어진다. 위에서 설정한 GROUP_SIZE는 각각의 태스크 셰이더 워크 그룹이 몇 개의 쓰레드로 실행되는가를 결정해준다. gl_localInvocationID가 바로 이 쓰레드의 id가 된다.

따라서, 다음 단계로 넘어갔을 때, 어디선가 100개(혹은 100개 그룹)의 데이터를 끌어오려면 해당 주소 값에 해당하는 배열 번호를 만들어낼 수 있어야 하는데, 결국 겹치지 않는 서로 다른 값들을 가져오려면 워크그룹 ID와 워크그룹 사이즈, 그리고 localInvocationID를 조합해서 0~100을 만들어야만 한다.
그래서 위의 코드에서는 baseID와 laneID 에 관련 정보를 넣어놓았다.
내장변수인 gl_WorkGroupSize 는 local_size_x = 32 로 정의해 준 수와 같은 32가 된다.
태스크 셰이더의 중요한 역할은 각각의 태스크 셰이더 워크그룹별로 몇 개의 메쉬셰이더 워크그룹을 생성할 것인가를 결정해주는 부분이다.
위에서는 총 4개의 태스크 셰이더 워크 그룹을 만들고 각 그룹에서 gl_TaskCountNV에 1을 할당했다. 따라서 4개의 mesh shader 워크그룹이 생겨나게 된다. 이 값을 지금처럼 상수로 넣지 않고, 셰이더 안에서 결정하여 동적으로 구성할 수 있다. LOD의 동적 조절에 이용할 수 있겠다.
메쉬 셰이더 단계로 보내는 구조체 앞에는 항상 taskNV out라는 문구를 써줘야 한다.
위에서 예로 든 Patch는 구조체 이름이므로 어떤 것을 써도 상관 없지만, 반드시(당연히) 메쉬 셰이더의 in 구조체와 이름을 맞춰줘야 한다.
특이한 점은 아래와 같이 구조체의 내용을 배열로 정의했다는 점이다.
uint baseID;
uvec3 workGroupSize;
uint laneID[GROUP_SIZE];
uint localInvocationIdx[GROUP_SIZE];
여기에 바로 전통적인 파이프라인과의 차이점이 드러나는데, mesh shader는 쓰레드간의 협동 모델이므로 변수도 공유하게 된다. 즉, 이 구조체의 내용은 32개 쓰레드에서 나누어 생성하지만 결국 32개 쓰레드에서 값을 공유한다.
따라서 같은 워크그룹ID를 지닌 32개 쓰레드의 경우 baseID와 workGroupSize가 같으므로 굳이 배열에 넣을 필요가 없다. 그리고 처리할 때도 다른 쓰레드에서 동시에 접근하지 않도록 laneID == 0 일때만 값을 쓰도록 했다.
배열의 크기의 경우, 여기서는 GROUP_SIZE와 맞춰주었지만 꼭 그럴 필요는 없다.
glLocalInvocationIndex 는 compute shader와 같은 방식으로 계산된다. 즉 다음과 같이 쓸 수 있다.
gl_LocalInvocationIndex =
gl_LocalInvocationID.z * gl_workGroupSize.x * gl_WorkGroupSize.y +
gl_LocalInvocationID.y * gl_workGroupSize.x +
gl_LocalInvocationID.x
그런데 mesh shader에서는 내장변수 uvec3 gl_LocalInvocationID 에서 y와 z값이 항상 0이다. const uvec3인 gl_WorkGroupSize 와 uvec3 gl_WorkGroupID, uvec3 gl_GlobalInvocationID 역시 x 값만 유효하고 y와 z는 항상 0임을 기억하자.
따라서 gl_LocalInvocationIndex 는 gl_LocalInvocationID.x 와 같은 값이 된다. 위의 예에서는 그냥 예시로 landID와 localInvocationIdx 두 개의 변수를 메쉬 셰이더 단계로 out 시켰으나, 결국 같은 값이라 실전에서 저렇게 사용할 필요는 없다. 그리고 workGroupSize 역시 상수값이므로 사실은 저렇게 굳이 저장공간을 사용하면서 넘길 필요가 없다.
위의 예를 다시 보면, 그래서 결국 baseID와 laneID 두 가지가 중요하다. 아무 처리내용도 없지만, 메쉬 셰이더 단계에서 이 out 변수 두 가지를 살펴봄으로써 어디에서 생성되었는지 출처를 알 수 있게 된다.
다시 강조하지만 쓰레드 숫자는 32개가 가장 좋다. 워프가 물리적으로 32개로 실행되기 때문이기도 하며, 추후에 설명하겠지만, 공유변수 셔플링을 통해 쓰레드간 빠르게 정보를 주고받을 때, 32개면 4 바이트 안에서 서로의 값을 읽어가면서 처리할 수 있다는 장점을 갖게 된다.
기본적인 mesh shader
그 다음은 mesh shader 단계다.
앞에서 4개의 mesh shader 워크그룹이 생겨났고, 여기서 GROUP_SIZE를 다시 32개로 정의했으므로, 32 x 4= 128개의 실행단위가 발생한다. 앞서 정해준대로, 필요한 단위는 100개이므로 그 한계를 검증하는 코드를 넣어야 한다.
우선 선언부 부터 보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#version 460 core
#extension GL_NV_mesh_shader : enable
//uniform은 크기를 지정해주어야 함
layout(binding = 0) uniform objectBuffer{
vec2 vertexVec[64];
};
layout (binding = 2, offset = 0) uniform atomic_uint list_counter;
layout (binding = 3, std430) buffer coordBuffer {float coord_buffer[];};
#define WARP_SIZE 32 //이 숫자가 메쉬 쉐이더와 다르면 미스매치 에러가 발생한다.
#define GROUP_SIZE WARP_SIZE
layout(local_size_x = GROUP_SIZE) in;
layout(max_vertices = 64, max_primitives = 126) out;
//layout(triangles) out;
//layout(lines) out;
layout(points) out;
taskNV in Patch{
uint baseID;
uvec3 workGroupSize;
uint laneID[GROUP_SIZE];
uint localInvocationIdx[GROUP_SIZE];
} meshin;
layout (location = 0) out MESHOUT{
vec4 color;
} meshout[];
uint index;
|
cs |
여기서는 data에 액세스해보자. 물론 task shader에서도 데이터에 액세스 할 수 있다.
위에서는 세 가지의 서로 다른 종류의 버퍼들을 바인딩했다. 당연히 바깥 코드에서도 맞춰줘야 한다.
각각의 mesh shader 워크그룹(쓰레드가 아님)에서 내보낼 점과 프리미티브의 숫자를 정의해준다. 예를 들어 사각형을 하나 그릴 경우에는 정점 네개와 프리미티브(triangle) 두 개가 되겠다.
각각 64개와 126개가 가장 효율적이라고 한다. 이것보다 많으면 다른 워크 그룹에서 처리해주는 것이 좋다는 말이다.
taskNV in 부분은 태스크 셰이더의 out과 정확히 일치해야 한다. 아니면 에러가 난다. GROUP_SIZE도 맞추어줘야 하지만 그 숫자를 태스크 셰이더의 local invocationID 숫자와 꼭 맞춰줄 필요는 없다. 내보낸 수만큼 메쉬 셰이더에서 액세스하지 않아도 된다. 그 모든 것들이 허용되지만, 그래도 배열의 값은 맞춰줘야 한다.
메쉬 셰이더에서 프래그먼트 셰이더로는 그냥 out 했다, 이 때는 버택스 개수와 일치하게 된다.
이제 main 함수를 보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
void main()
{
//이 워크그룹 전체(size=32)에 대한 프리미티브 개수다.
//코드를 제대로 짜 본다면, 네번째 워크그룹에서는 64개가 아니라 8개가 되도록 수정해야 한다.
gl_PrimitiveCountNV = 64;
uint baseID = meshin.baseID;
uint laneID = meshin.laneID[gl_LocalInvocationID.x];
uint offset = baseID + laneID;
if (offset<100)
{
//병렬처리될 수 있도록 잘 짠다. 워크그룹이 모두 수행된 후 프리미티브가 생성된다.
gl_MeshVerticesNV[gl_LocalInvocationID.x*2].gl_Position
= vec4(vertexVec[offset].x,
vertexVec[offset].y, 0, 1.0);
gl_MeshVerticesNV[gl_LocalInvocationID.x*2+1].gl_Position
= vec4(vertexVec[offset].x+0.01,
vertexVec[offset].y, 0, 1.0);
gl_PrimitiveIndicesNV[gl_LocalInvocationID.x*2] = gl_LocalInvocationID.x*2;
gl_PrimitiveIndicesNV[gl_LocalInvocationID.x*2+1] = gl_LocalInvocationID.x*2+1;
meshout[gl_LocalInvocationID.x*2].color
= vec4(vertexVec[offset].x, vertexVec[offset].y, 0, 1.0);
meshout[gl_LocalInvocationID.x * 2 +1].color
= vec4(vertexVec[offset].x, vertexVec[offset].y, 0, 1.0);
}
}
|
cs |
메쉬 셰이더에는 발생시킬 프리미티브의 개수를 명시해주어야 하는데, 이 개수는 쓰레드마다 할당되는 것이 아니라 워크그룹마다 할당된 개수라는 점을 확실히 기억하자. 결국 메쉬 셰이더는 이 점과 이만큼의 프리미티브를 발생시키기 위해 32개를 어떻게 분할해서 운용할지 결정하는 프로그래밍을 해야 한다. 위에서는 비교적 단순하게 했다.
앞에서 가져온 로컬 id 등을 바탕으로 인덱싱을 한다. 앞서 언급한 것처럼 바인딩한 버퍼에서 읽어올 시작점을 offset 변수로 결정하게 된다.
메쉬 셰이더는 두 개의 내장변수를 통해 vertex와 index를 내보낸다. 다시 말해, 정점 좌표와 인덱스를 동시에 내보내서 인덱스 방식으로 그린다고 생각하면 된다.
필수적으로 gl_MeshVerticesNV는 버텍스 속성을 내보낸다. 같은 워크그룹 안에서 0번 인덱스부터 시작한다. gl_PrimitiveIndicesNV는 인덱스를 내보낸다. 역시 같은 워크그룹 안에서 0번 인덱스부터 시작한다.
평범해 보일 수도 있지만 이 부분에 바로 메쉬 셰이더의 장점이 들어있다. 정점 재사용(vertex-reuse)라는 것인데, 예를 들어 점을 0,1,2,3,4를 방출한 후 인덱스에서 0,1,2 /1,2,3 /2,3,4로 호출할 경우 혹은 그렇지 않더라도 Max vertex에서 선언된 만큼은 캐시 안에서 정점 재사용이 가능하다. 다시 말해 빠른 캐시 메모리를 이용함으로서 vram에서 정점을 읽어들이는 무거운 작업이 한 번만 이루어지고, meshVerticesNV에 등록된 정점 중 인덱스에서 반복적으로 호출하는 정점은 캐시에서 빠르게 읽어들이게 된다.
참고로 버텍스와 인덱스는 모든 쓰레드가 끝난 후에 워크 그룹 안에서 종합한다. 1번 쓰레드에서 버텍스 0번과 1번을 내보내고, 인덱스는 0번 8번 9번을 호출해도 상관없다는 말이다. 물론 쓰레드 어딘가에서 8번과 9번을 방출해야 한다.
기존의 경우라면 barrier( ) 같은 함수를 호출해서 동기화 시킨 후 다음으로 넘어가야 하겠지만, mesh shader에서는 그 부분이 필요가 없다. 아마도 내부적으로 동기화가 구현되었거나 실시간으로 다른 쓰레드의 내용을 공유하는 기술을 쓰는 것 같다.
약간 까다로운 점은 앞에서 정의한 gl_primitiveCountNV로 정의해준 수와, 아래서 변수값을 통해 구성한 내보내는 수가 정확히 일치해야 한다는 부분이다. 이를 검증하는 코드를 넣지 않으면, 데이터를 알아서 잘라주지 않은 채 굉장히 기이하게 깨진 화면을 볼 수 있게 된다. 여기서는 그 부분을 생략했다. 뒤에 나오는 예시에는 제대로 실행되는 코드를 넣었으니 참고바란다.
또한, 점을 10개 방출하고 인덱스를 8까지 사용하는 것은 문제 없으나, 인덱스가 없는 점을 가리킬 경우에도 화면이 깨지게 되니 주의하자.
meshout은 앞서 정의해준, 프래그먼트 셰이더로 내보내는 변수다. 지금은 점 기준이므로 위처럼 vertices개수와 일치시켰다. 컬러 값이지만 그냥 nomalized 된 값이라고 가정하고 버텍스 값으로 사용할 용도로 바인딩한 버퍼 값을 그대로 넣었다.
여기까지의 셰이더 구성을 통해 무엇인가를 그릴 수 있다. 물론 프래그먼트 셰이더도 있지만, 기존 파이프라인에서의 형식과 완전히 동일하므로 여기서는 설명을 생략했다.
그런데 의문이 들 것 같다. 도대체 메쉬 셰이더의 특별한 점이 무엇인가?
메쉬 셰이더의 필수 문법만 포함시켜서 코드를 작성해보면 그냥 정점과 인덱스를 내보내서 개체를 그릴뿐이다. 오히려 그 방식이 번거롭게만 느껴진다. 사실 그렇다. 메쉬 셰이더 문법 자체에는 아무런 장점이 없는 것처럼 보인다. 밀어넣은 점들을 순차적으로 받아들여서 그리는 전통적 파이프라인에서는 특정한 점의 앞과 뒤만 생각하면서 셰이더를 작성하면 되는데, 여기서는 오히려 받아들이는 순서조차 신경써야 하고, 동시에 진행되는 쓰레드에서 어떻게 작업을 분할할 것인지조차 부족하거나 넘침 없이 변수의 수를 계산해주어야 하기 때문이다.
그런데 바로 그 지점에 장점 또한 존재한다. 점들을 선택적으로 끌어오므로 LOD를 결정하면 해당 점들만 읽을 수 있기 때문이다. 그렇다면 메쉬 셰이더 장점의 핵심인 동적 생성, 그리고 그것을 가능하게 하는 부가적 extension 의 사용에 대해 알아보자.
부가적인 내용 : task shader 단계에서 워크그룹의 동적 생성을 도와주는, 32개 thread간의 실시간 데이터공유
앞에서는 task shader와 mesh shader의 가장 기본적인 문법과 요소들을 알아보았다. 엔비디아에서도 자신들이 만든 메쉬 셰이더를 많은 사람들이 쓰기를 원했다면 좀 더 친절하게 설명해주었으면 좋을텐데, 아쉽게도 그게 없었던 탓에 결국 하나하나 빼보면서, 혹은 곰곰이 생각해보면서 알아내야만 했다. 이를테면 OpenGL 교재 같은 것들에 나오는 '삼각형 하나를 그리는 vertex shader 와 fragment shader 예제' 같은 것 말이다.
여튼, 위처럼 세이더를 구성함으로써 어떤 것이 메쉬 셰이더의 필수요소이고, 어떤 것이 부가적인 부분인지 구분할 수 있게 된다. 그렇다면 이제는 그 장점을 이용하기 위해 부가적인 부분들을 배워보자.
첫 번째로, task shader는 다음 단계인 mesh shader의 생성 개수를 조절할 수 있다는 특징이 있다. 이 특징을 이용하여 LOD를 다르게 구성할 수 있다. 혹은 컬링 작업에 이용할 수도 있다.

nvidia 의 설명 글에 있는 위의 다이어그램을 보면 태스크쉐이더의 workgroup 0번은 mesh shader를 1개만 생성했고, 1은 0개 생성하고 2는 메쉬 셰이더를 2개 생성했다. 고정된 수의 자식을 생성하지 않고, 이렇게 필요에 따라 유연하게 생성하려면 생성된 자식에 관련 정보를 보낼 수 있어야 한다. 그 장치들을 알아보자.
#version 460 core
#extension GL_NV_mesh_shader : require
#extension GL_NV_shader_thread_group : require
#extension GL_NV_gpu_shader5 : require
우선 task shader 의 선언부에 두 개의 extension 을 더 추가해주어야 한다. 이 extension 들 역시 Nvidia 의 확장 사양이며, 앞에서 구성한 glad.c 에 모두 포함시켜놓았다.
GL_NV_gpu_shader5 는 1바이트나 2바이트 int 변수를 사용하기 위해 필요하다.
GL_NV_shader_thread_group 은 ballotThreadNV 함수를 제공하는데, 이게 핵심이다. nvidia 의 사양 설명을 보면 다음과 같다.
Syntax:
uint ballotThreadNV(bool value)
The function ballotThreadNV() computes a 32-bit bitfield. It looks at the condition <value> for each active thread of a thread group and set to 1 each bit for which the condition in the corresponding thread is true. Bits for threads with false condition are set to 0. Bits for inactive threads are also set to 0. It's possible to query the active thread mask by calling the function activeThreadsNV.
ballotThreadNV는 32bit로 구성된 비트 필드를 통해, 쓰레드 그룹 안에서 동시에 활성화 된 쓰레드들을 조사하는데 쓰인다. 넣은 값이 true인 쓰레드들의 해당 비트필드들을 모두 1로 바꾼다. 어떤 쓰레드에서 false를 넣었다면, 해당 쓰레드는 0으로 바꾼다. 활성화되지 않은 쓰레드도 0으로 남겨둔다.
다시 설명하자면, 셰이더 코드를 작성할 때 함수에 매개변수로 true나 false 를 전달한다. 다음과 같은 형식이다.
uint vote = ballotThreadNV(render)
그런데 vote 변수에는, 동시에 병렬적으로 진행되는 다른 31개의 쓰레드의 값을 종합한 결과가 들어간다. barrier() 와 같은 동기화 작업 없이 이게 어떻게 가능한지는 아래의 글에 설명되어 있다.
Reading Between The Threads: Shader Intrinsics
When writing compute shaders, it’s often necessary to communicate values between threads.
developer.nvidia.com
공유메모리를 사용하는 것은 아니지만 다른 쓰레드의 상태를 알 수 있으며, 그보다 빨리 작동한다고 한다. 메모리 동기화가 필요 없다.
이 특징을 어떻게 이용할까?
이제 해당 함수들을 사용한 코드를 보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
bool render = isInsideFrustum(thisMargin);
vec4 point0 = PMV * vec4(XBASE + (xcoor * TASKWIDTH), YBASE + (ycoor * TASKHEIGHT), 0, 1);
vec4 point1 = PMV * vec4(XBASE + ((xcoor+1) * TASKWIDTH), YBASE + ((ycoor+1) * TASKHEIGHT), 0, 1);
float pixelWidth = length(screen * distance(point0.xy / point0.w, point1.xy / point1.w)*0.5);
if (pixelWidth < 70.0) {
render = (laneID == 0) ? render && true : false;
}
else if (pixelWidth < 100.0) {
render = render && lod1[laneID];
}
uint vote = ballotThreadNV(render); //활성화 된 모든 쓰레드 표시
uint tasks = bitCount(vote); // 활성화 된 모든 쓰레드의 개수 세기
if (laneID == 0) {
gl_TaskCountNV = tasks;
}
|
cs |
첫 번째 줄에서는 프러스텀 컬링의 결과를 얻고 두 번째부터 그 아래에서는 화면에서 보이는 객체의 크기를 계산해서 LOD를 결정한다.
여기서 중요한 부분은 13번 줄 부터다. 이 태스크 셰이더는 32개로 돌아가는데, ballotThreadNV는 32bit field에서 각각 쓰레드의 bool render 값에 따라 0 혹은 1로 표시를 한다. 함수에는 쓰레드 고유 번호를 매개변수로 보내지 않지만, ballotThreadNV 가 알아서 해당 쓰레드번호에 해당하는 비트를 마킹해준다.
재미있는 건, 이 결과를 32개 쓰레드가 공유한다는 점이다. 그래서 다음 줄에서 vote 변수 중 1로 된 bit를 세게 되면 tasks 변수에는 결국 32개 쓰레드 중 mesh shader로 보낼 유효한 쓰레드의 수가 담긴다. bitCount는 32개 bit 중 참인 값의 수를 정수로 센다. 예를 들어 비트 값이 0000000011010001 이면 4가 되겠다. 참고로 여기에서 설정한 tasks 변수 값은 이 태스크 셰이더 32개 쓰레드 한 묶음이 생성하는 메쉬 셰이더의 워크그룹 수를 결정하는 데 사용될 것이다. tasks가 2라면 앞서 첨부한 Nvidia의 다이어그램에서 맨 우측 경우가 된다.
shared memory를 쓸 경우와는 달리 barrier로 동기화 하지 않아도 정상적으로 작동한다는 점이 이 장치의 최대 장점이다. nvidia에서도 공유메모리보다 이 방식이 더 빠르다고 말한다.
그리고 32개 쓰레드 각각에서 mesh shader의 워크그룹으로 이어지는 것이 아니라, 동일 워크그룹인 32개 쓰레드의 결과를 종합하여 mesh shader의 워크그룹 수를 결정하게 된다. (위에서 TREE EXPANSION 이라고 이름 붙은 엔비디아 다이어그램 참고) 그러므로 위에서 laneID 가 0일때, 즉 32개 쓰레드 중 한 곳에서만 gl_TaskCountNv 값을 전달하도록 했다.
task shader 단계에서 프러스텀 컬링 작업을 할 경우, 점들을 그룹으로 다루는 meshlet(인접한 삼각형들의 그룹) 방식과 결합되면 효율성 측면에서 상당한 이득을 얻는다. meshlet으로 분할된 부분들 중 한 정점의 값만 읽어서 절두체 포함 여부를 결정한 후 mesh shader로 정보를 넘겨주면 되기 때문이다. 즉 초기 단계에서 최소한의 정점에 액세스하여 결정하는 것인지라 대단히 빠르게 진행시킬 수 있다. 전통적인 파이프라인에서는 모든 점들을 거쳐야 하므로 비효율적인데, 사실 그 파이프라인 상에서는 선택적으로 취하거나 버리면서 삼각형을 구성하기도 애매하다. 따라서 cpu로 작업하거나 compute shader로 매 프레임마다 드로잉 이전에 pre-processing을 해야 한다.
참고로, 이 frustum culling 방식은 cpu 혹은 gpu 중 어느 곳에서 할 것인지에 대한 시도와 연구가 많은 것 같다. 이를테면 아래와 같은 글이 있다. 작년에 찾아봤을 때는 코드 구현 부분이 깔끔하게 잘 보였는데, 지금은 코드들이 라인 분할이 안 된채로 보인다.
Frustum Culling
Introduction Frustum culling is process of discarding objects not visible on the screen. As we don't see them ?EUR" we don't need to spend
gamedev.net
위의 글에서는 frumsum culling을 cpu 에서 하는데, 멀티 쓰레딩, SSE 를 활용한 방식, GPU , 혹은 기본 비교 형틀을 AABB인지 OBB 인지 등 여러가지 시도를 하고 있다. 댓글에서는 AVX 기술을 써보았냐는 언급도 있는 것을 보니 기존에도 여러가지 시도들이 꾸준히 있었던 것 같다. 메쉬 셰이더 방식이 이런 시도들보다 훨씬 빠른지는 모르겠으나, 여하튼 컬링이 드로잉 이전의 프리프로세싱이 아니게 되어버렸다는 점에서, 즉, 결과를 중간 과정에 한번 더 저장하지 않아도 된다는 점에서는 많은 이득이 있을 것 같다.
다시 원 글로 돌아오자.
동적인 mesh shader 개수를 생성할 때 필요한 테크닉이 또 한가지 있다. 만약 mesh shader 단계로 5개 워크그룹을 생성하여 넘겨줄 때, task shader 마지막에서는 어떤 배열 변수를 만들어서 넘겨줄 데이터들을 담아야 한다. 그런데 생각해보자. 그 배열의 몇 번 방에 데이터를 쓸 것인가?
아래의 코드에서 idxOffset 변수가 바로 이와 연관된 부분이다. 위와 같은 task shader의 나머지 다른 부분이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
taskNV out Task{
uvec4 cellID[GROUP_SIZE];
} OUT; //여기서 지정하는 수는 mesh shader와 반드시 맞아야 한다.
if (render) {
uint idxOffset = bitCount(vote & gl_ThreadLtMaskNV);
//and 연산을 통해 배열 번호를 계산한다.
//cellID는 land의 배열번호에 사용할 것임
uint x = xcoor * (TASKWIDTH / UNIT) + xlane * 7;
uint y = ycoor * (TASKHEIGHT / UNIT) + ylane * 7;
if (pixelWidth < 70.0) {
OUT.cellID[idxOffset] = uvec4(x, y, 8, 4);
}
else if (pixelWidth < 100.0) {
OUT.cellID[idxOffset] = uvec4(x, y, 4,4);
}
else {
OUT.cellID[idxOffset] = uvec4(x, y, 1,1);
}
}
|
cs |
위에서 가장 중요한 부분은 idxOffset을 계산하는 부분이다. 한번 생각해보자. 32개 쓰레드에서 5개를 render하기로 결정했고, 그래서 5개의 tasks를 생성했다. 메쉬 셰이더로 out 할 때 cellID는 몇 번 배열에 쓸 것인가?
일단 가정을 해보자. 그냥 1번 쓰레드(1~32중 1)는 0번 배열(0~31중 0)에, 7번 쓰레드는 6번 배열에. 이런 방식으로 0,6,9,11,14번 배열에 담에 메쉬 셰이더로 보냈다고 해보자. 어쨌든 5개의 워크그룹을 생성했다는 정보를 gl_TaskCountNV 변수를 통해 넘겨 주었으므로 워크그룹은 5개가 생성되었을 것이다.
그렇다면 메쉬 셰이더에서 받아올 수 있는 내장 변수는 메쉬 셰이더 자체의 workGroupID인데, 이것은 0,1,2,3,4가 된다. 그렇다면 태스크 셰이더로부터 정보들을 넘겨 받은 메쉬 셰이더 입장에서는 6,9,11,14번의 배열을 읽을 수 있는 단서가 사라지게 된다. 다시 말하자면, 이전 단계에서 7번 쓰레드가 통과하고 8번이 통과하지 못했다는 정보는 알 방도가 없다. 결국 32개의 모든 방들을 읽으면서 값이 쓰여진 방들을 찾아내야 한다는 것인데, 그렇다면 5개의 워크 그룹이 이 작업을 어떻게 분할할 것인가의 문제가 생긴다.
자, 그렇다면 이번에는 이런 문제를 피하기 위해, task shader 단계에서 0,1,2,3,4번 방에 값을 쓰려고 해보자. 이번에도 문제가 발생한다. 1번 쓰레드는 0번 방에 쓴다고 하고, 그 다음 7번 쓰레드는 몇 번 방에 쓸 것인가? 1번 방에 쓰고 싶기는 한데, 2,3,4,5,6번 쓰레드에서 false의 결과를 받았다는 것을 어떻게 알 것인가? 다시 말하자면, 1번 쓰레드부터 true인 순번이 두번째라는 사실을 어떻게 알아낼 것인가?
그래서 필요한게 아래의 장치다.
gl_ThreadLtMaskNV는 해당 쓰레드 번호까지 1번을 마스킹한 NV확장 내장변수다. 7번 쓰레드라면 1이 6개 마스킹 된 다음의 값을 가져온다. Lt는 less than이라는 의미다. 그리고 여기서 말하는 쓰레드 번호 1번은 1~32까지 중에서 1번이다. (0~31번이 아님)
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
이제 vote는 다음과 같을 것이다. 편의상 1만 표시했다.(0,6,9,11,14번 배열에 1 표시)
|
|
|
|
|
|
1 |
|
|
1 |
|
1 |
|
|
1 |
|
|
|
|
|
1 |
이제 두 변수를 AND연산하면 0번 비트의 1만 남는다. bitcount는 1이 된다. 따라서 7번 쓰레드(1~32중 7)는 넘겨지는 5개 중 이 bitcount의 값과 같은 0번 배열(0~31중 0)에 값을 넣어 보내게 된다. 같은 방식으로 하면 10번 쓰레드는 1번방, 12번 쓰레드는 2번방에 들어갈 수 있음을 확인할 수 있다. 그래서 0번 배열부터 누적시켜 보낼 수 있으며 메쉬 셰이더에서도 0,1,2,3,4번을 읽으면 된다.
(좀 더 부연하자면, 1번 쓰레드는 0 개의 1 반환, 2번 쓰레드부터 7번쓰레드까지는 모두 1개의 1 반환, 8번쓰레드부터 10번 쓰레드까지는 2개의 1을 반환한다.)
배열의 순번을 알아냈으니 이제는 필요한 값을 기록하면 된다. 여기서는 LOD를 총 4 단계로 구분한 후, 각각의 배열에 필요한 값을 넣었다. 여기서는 x,y 즉 지형을 그릴 좌하단 좌표점, 그리고 LOD 에 따른 x,y, 증분인 (8,4), (4,4), (2,2), (1,1)을 같이 넣어 보냈다.
참고로, 이 코드에서 입력으로 사용한 지형데이터는 다음과 같이 구성했다.

우리나라 국토 전체를 커버하는 크기의 지형을 25m 간격으로 분할했는데, 하나의 unit 을 1400x700m로 설정했다. 따라서 가로 462개 x 세로 877개 = 405,174 개의 unit을 처리해야 한다. 따라서 C++에서는 다음과 같이 드로우콜을 보냈다.
glDrawMeshTasksNV(0, 462*877);
따라서 워크그룹 ID가 0~405173까지 생성되므로 task shader에서 워크그룹 ID와 462라는 상수값을 이용해서 해당 블록의 x,y 좌표값을 계산할 수 있다.
하나의 워크그룹은 32개의 thread로 구성되므로, 각각의 thread에서는 다음과 같이 175m x 175m 의 공간을 다루도록 했다.

이제 화면상에서 시점과의 거리에 따라 LOD를 4단계로 결정한다.

가장 덜 자세한 LOD1 단계로 결정되면, 하나의 워크 그룹(1400m x 700m 공간)에서 1개의 mesh shader를 발생시킨다. 0번 쓰레드만 true로 처리한다. 1개의 mesh shader는 할당받은 공간을 가로 7등분, 세로 7등분한 후 64개의 정점을 통해 그리게 된다. 따라서 가장 덜 자세하게 그릴 때 정점들의 가로 세로 간격은 각각 200m, 100m씩 떨어지게 된다.
LOD2 단계로 결정되면, 0번 4번 쓰레드만 true로 처리한다. 즉 2개의 mesh shader 워크그룹을 발생시킨다. 정점들의 가로세로 간격은 각각 100m 씩 떨어지게 된다. 검은색 테두리가 바로 1개 mesh shder 에서 다루게 될 공간의 크기다.
LOD3 단계로 결정되면, 0,2,4,6,16,18,20,22번 쓰레드를 true로 처리한다. 8개의 mesh shader 워크그룹을 발생시킨다. 정점들의 가로세로 간격은 각각 50m씩 떨어지게 된다.
가장 자세한 LOD4 단계로 결정되면, 32개 모든 쓰레드를 true로 처리한다. 즉, 하나의 워크 그룹에서 32개의 mesh shader를 발생시킨다. 1개의 mesh shader는 마찬가지로 가로세로 7등분한 후 64개의 정점을 통해 그리게 된다. 정점 64개는 mesh shder에서 캐시를 고려하여 권장하는 수치다. 그래서 가장 자세하게 그릴 때는 가로세로 25m 간격으로 그리게 된다.
LOD4 단계에서 mesh shader 1개 워크그룹에서 다루는 양을 보자.
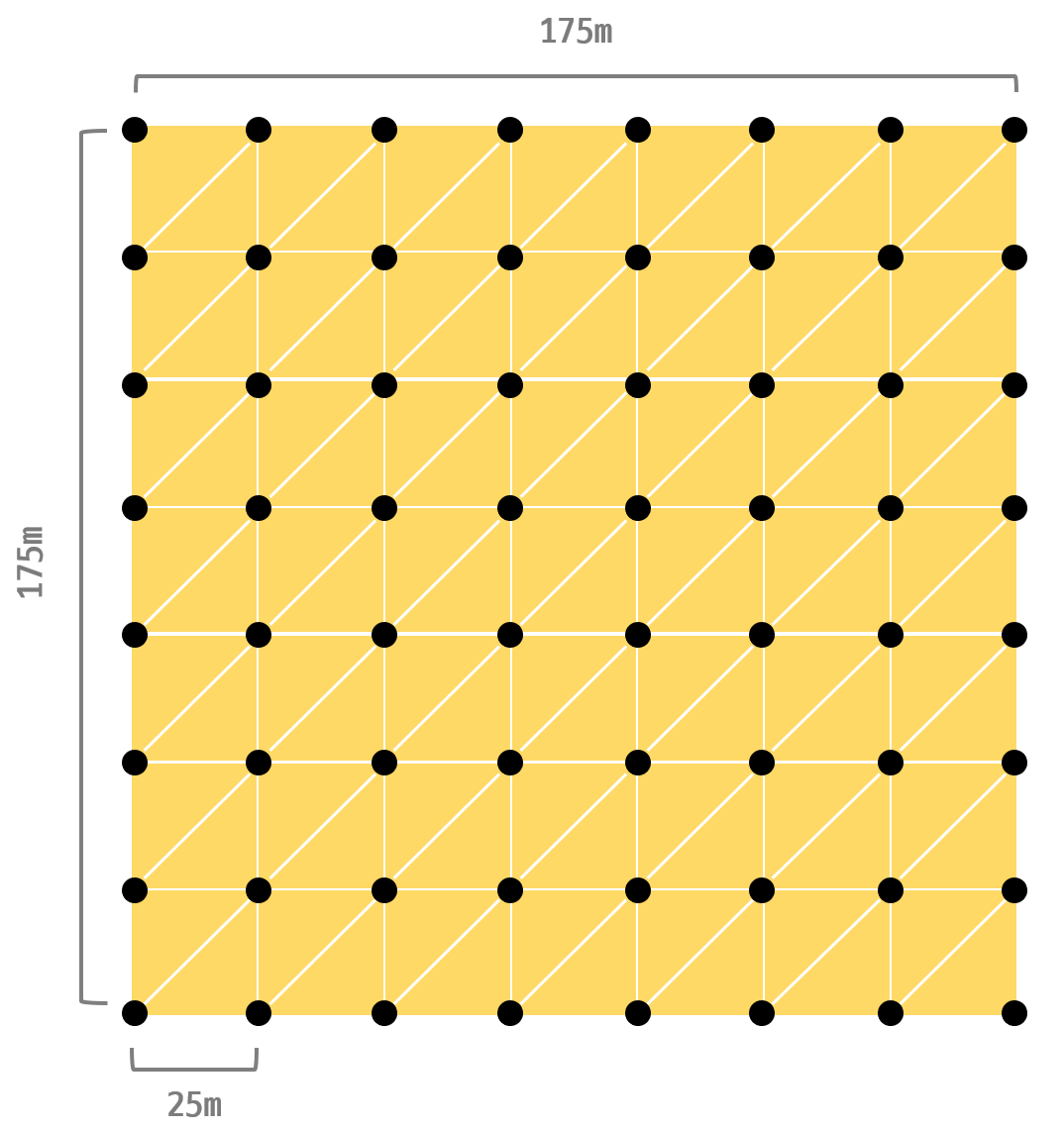
위와 같이 LOD4 단계에서 지형은 가로세로 25m 간격을 지닌 64개 vertex와 98개 primitive(triangle)로 그려진다. 이만큼의 양을 1개 워크 그룹의 32개 쓰레드가 협동적으로 그리게 된다. 32개 각각의 쓰레드는 2개의 정점과 9~12개의 인덱스를 방출할 것이다. 삼각형 하나당 3개의 정점이 필요하다. 메쉬 셰이더에서는 전통적 파이프라인과는 달리 line strip 이나 triangle strip 방식은 없다.
각 정점의 xy좌표는 배열번호를 통해 구할 수 있으므로, 정점의 높이만을 2byte 안에 담았다. 따라서, 지형 데이터 전체 높이들 중 최소값과 최대값 사이를 65536등분한 후, 원래 높이를 그 구간에 snap을 걸듯이 맞춰서 보정했다.
예를들어 우리나라 지형 높이 중 최소값이 -48m 이고, 최대값이 2000m 라면, 모든 높이들은 65536 / 2048 = 32m 간격으로 재조정되어 unsigned int 값으로 저장된다. 즉, 높이의 해상도는 32m가 된다. 그러므로 모든 지형은 가로세로 25m, 높이방향 32m 의 해상력을 가지는 그리드에 맞춰서 단순화되었다고 보면 된다.
이제 마지막으로,
32개의 쓰레드로 구성되는 하나의 task shader 워크그룹에서 만들어낸 정보는, 그 task shader가 만들어내는 mesh shader 전체에서 접근할 수 있다는 점을 기억하자.
맨 처음에 예시로 든 코드에서는 1개의 task shader 워크그룹이 1개의 mesh shader 워크그룹을 생성시켰으며, baseID와 laneID를 메쉬 셰이더로 넘겨서 해당 정보로 태스크 셰이더의 output에 액세스했는데 여기서는 그렇지 않다. 약간 다르게 구성했다.
다시 설명하자면, 앞에서 든 예는 태스크 셰이더 워크그룹 0번에서 32개의 배열에 값을 넣은 후, (단 한개만 만들어진) 메쉬 셰이더 워크그룹 0번을 구성하는 32개의 쓰레드에서 32개 배열 각각의 방에 액세스 했다.
반면, 여기서는 메쉬 셰이더 워크그룹 0번에서 cellID[0]번의 정보를 액세스 한 후, 0번 워크그룹의 32개 쓰레드에서 cellID[0]번의 데이터를 바탕으로 지형을 구성하는 삼각형을 협동적으로 생성할 것이다.
또한 메쉬 셰이더 워크그룹 1번에서 cellID[1]번의 정보를 액세스 한 후, 1번 워크그룹의 32개 쓰레드에서 cellID[1]번의 데이터를 바탕으로 지형을 구성하는 삼각형을 협동적으로 생성할 것이다. 모든 것은 구성하기 나름이다.
그림으로 설명하면 아래와 같다.
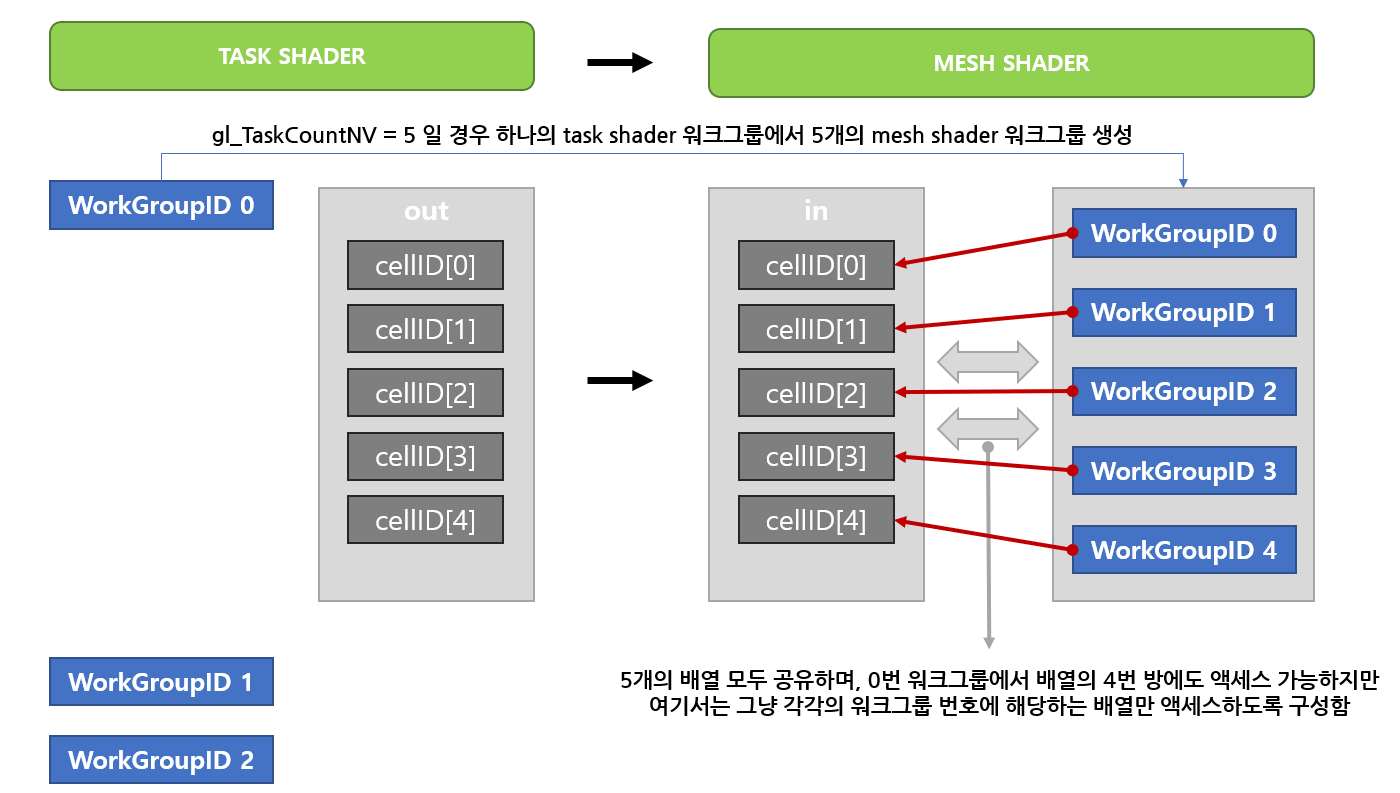
또 예를 들자면, 태스크 셰이더 워크그룹 0번에서 5 x 32 = 160개의 배열을 생성한 후 정보를 넣고, 5개의 메쉬 셰이더 워크그룹을 생성한 후, 5개 워크그룹 각각 32개 쓰레드, 총 160개 쓰레드에서 앞서 만든 배열 각각의 방에 액세스 해도 된다.
처음에 메쉬 셰이더 코드를 작성할 때 엔비디아에서는 자세히 설명해주지 않는 이런 규칙들이 가장 헷갈렸었다. 결국은 여러가지를 시도해보고 깨닫는 수 밖에 없었다.
부가적인 내용 : mesh shader 에서 발생시키는 점과 index 수 맞추기
vertex shader는 점들을 한번에 보내면 되고, 병렬 처리과정은 크게 신경쓰지 않아도 된다. 그렇지만 메쉬 셰이더는 32개 쓰레드에서 어떻게 삼각형을 분배해서 그릴 것인지 반드시 미리 계산해야 한다.
아래의 예는 정점 8x8 = 64로 이루어진 지형 patch를 그린다. 32개 쓰레드이므로 한 쓰레드에서 정점 2개만을 내보내면 되지만, 정점을 내보낼 때 연관 삼각형의 normal 값을 같이 내보내기 위해서 여섯 개 점을 함께 읽고 있다. 작업의 효율을 위해서는 노멀을 미리 계산해서 메모리에 넣는 방법이 있다. 그러면 점 2개, 노멀 2개를 읽게 되므로 메모리 액세스가 줄어들 수 있다. 상황에 따라서 잘 적용해야 한다.
아래의 예는 아예 정점 당 색상을 계산해서 보내고 있다. vertex out이 4가 된 이유는 패치의 위치 하나당 지형레벨 하나, 0레벨 하나로 두 개를 보내기 때문이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
//현재 32개 쓰레드 안에서의 배분. 8X8 격자에서 할당한다.
uint ylane = uint(laneID / 8);
uint xlane = laneID - ylane * 8;
//LAND 데이터에 적용시킬 수 있는 좌표가 된다.
//x는 하나당 하나, y는 하나당 두 줄씩 배분. 64개 점을 32개 안에서 해결해야 함
uint xcoor = cellID.x + cellID.z * xlane; //0~7
uint ycoor = cellID.y + cellID.w * ylane * 2; //0,2,4,6
/*
h3 -- h3r v2 v5
| \ |
| \ |
h2 -- h2r v1 v4
| \ |
| \ |
h1 -- h1r v0 v3
*/
//점 하나와 그 위의 점(0번과 8번)
int h1 = int(land[ycoor].x[xcoor]);
int h2 = int(land[ycoor + (1 * cellID.w)].x[xcoor]);
int h3 = int(land[ycoor + (2 * cellID.w)].x[xcoor]);
int h1r = int(land[ycoor].x[xcoor + (1 * cellID.z)]);
int h2r = int(land[ycoor + (1 * cellID.w)].x[xcoor + (1 * cellID.z)]);
int h3r = int(land[ycoor + (2 * cellID.w)].x[xcoor + (1 * cellID.z)]);
float hh1 = float(h1 / 32.0) - 48.0;
float hh2 = float(h2 / 32.0) - 48.0;
float hh3 = float(h3 / 32.0) - 48.0;
float hh1r = float(h1r / 32.0) - 48.0;
float hh2r = float(h2r / 32.0) - 48.0;
float hh3r = float(h3r / 32.0) - 48.0;
vec3 vertex0 = vec3(XBASE + xcoor * 25, YBASE + ycoor * 25, hh1 * scaleZ);
vec3 vertex1 = vec3(XBASE + xcoor * 25, YBASE + (ycoor + (1* cellID.w)) * 25, hh2 * scaleZ);
vec3 vertex2 = vec3(XBASE + xcoor * 25, YBASE + (ycoor + (2 * cellID.w)) * 25, hh3 * scaleZ);
vec3 vertex3 = vec3(XBASE + (xcoor + (1 * cellID.z)) * 25, YBASE + ycoor * 25, hh1r * scaleZ);
vec3 vertex4 = vec3(XBASE + (xcoor + (1 * cellID.z)) * 25, YBASE + (ycoor + (1 * cellID.w)) * 25, hh2r * scaleZ);
vec3 vertex5 = vec3(XBASE + (xcoor + (1 * cellID.z)) * 25, YBASE + (ycoor + (2 * cellID.w)) * 25, hh3r * scaleZ);
//여기까지는 그리드 좌표 형태로 압축시켜놓은 xy좌표와,
//2byte로 압축시켜놓았던 높이 값을 원래 값들로 되돌리는 과정이다.
//노멀벡터 계산
vec3 normal0 = normalize(cross(vertex3 - vertex0, vertex1 - vertex0));
vec3 normal1 = normalize(cross(vertex1 - vertex4, vertex3 - vertex4));
vec3 normal2 = normalize(cross(vertex4 - vertex1, vertex2 - vertex1));
vec3 normal3 = normalize(cross(vertex2 - vertex5, vertex4 - vertex5));
float cosT0 = dot(lightNormal, normal0)*0.5 + 0.5;
float cosT1 = dot(lightNormal, -normal0)*0.5 + 0.5;
vec4 color1 = cosT0 > cosT1 ? cosT0 * cosT0 * lightColor : cosT1 * cosT1 * lightColor;
//점 방출. 0의 위아래, 16의 위아래 4개씩
//반드시 인덱스 방식으로 그려야 하는 것은 아니다.
gl_MeshVerticesNV[ylane * 16 * 2 + xlane * 2].gl_Position = Projection * View * vec4(vertex0, 1.0);
gl_MeshVerticesNV[ylane * 16 * 2 + xlane * 2 +1].gl_Position = Projection * View * vec4(vertex0.xy, 0, 1.0);
gl_MeshVerticesNV[ylane * 16 * 2 + xlane * 2 + 16].gl_Position = Projection * View * vec4(vertex1, 1.0);
gl_MeshVerticesNV[ylane * 16 * 2 + xlane * 2 + 16 + 1].gl_Position = Projection * View * vec4(vertex1.xy, 0, 1.0);
/*
//프래그먼트 셰이더로 내보내는 구조체를 아래와 같이 정했다.
out MESHOUT{
vec4 color;
float t;
} meshout[];
*/
vec4 landcolor = mix(vec4(0.1, 0.15, 0.1, 1.0), vec4(landcolorin, 1.0), hh1 / 2000.0);
//여기서의 배열 번호에 따른 속성은 gl_MeshVerticeNV의 같은 배열 번호의 정점들과 자동적으로 매칭된다.
meshout[ylane * 16 * 2 + xlane * 2].color = landcolor;
meshout[ylane * 16 * 2 + xlane * 2 + 1].color = color1;
meshout[ylane * 16 * 2 + xlane * 2 + 16].color = landcolor;
meshout[ylane * 16 * 2 + xlane * 2 + 16 + 1].color = color1;
meshout[ylane * 16 * 2 + xlane * 2].t = 1.0;
meshout[ylane * 16 * 2 + xlane * 2 + 1].t = 0.0;
meshout[ylane * 16 * 2 + xlane * 2 + 16].t = 1.0;
meshout[ylane * 16 * 2 + xlane * 2 + 16 + 1].t = 0.0;
|
cs |
gl_MeshVerticesNV 는 다음과 같은 내용으로 구성되는 built-in 구조체다.
out gl_MeshPerVertexNV {
vec4 gl_Position;
perviewNV vec4 gl_PositionPerViewNV[]; // NVX_multiview_per_view_attributes
float gl_PointSize;
float gl_ClipDistance[];
perviewNV float gl_ClipDistancePerViewNV[][];
float gl_CullDistance[];
perviewNV float gl_CullDistancePerViewNV[][];
} gl_MeshVerticesNV[];
여기서는 필수 속성에 해당하는 gl_Position 만 사용하였으나, 다른 값들도 필요에 따라 이용하면 된다.
메쉬 셰이더를 제대로 쓰려면 아래의 스펙은 꼭 한번 읽어보기를 권한다.
KhronosGroup/GLSL
GLSL Shading Language Issue Tracker. Contribute to KhronosGroup/GLSL development by creating an account on GitHub.
github.com
마지막의 meshout 은 프래그먼트 셰이더로 내보내는 값들이다. 배열번호가 같은 정점과 meshout 값들이 매칭된다.
이렇게 32개 쓰레드에서 128개 정점과 98개 삼각형을 내보내기 위해서 아래와 같은 분할 장치를 사용하였다. 태스크 셰이더에서 사용한 ballotThreadNV를 응용하여 두 개 사용하고, 두 개의 bool 값 여부에 따라 어떤 쓰레드에서는 삼각형 2개를, 어떤 쓰레드에서는 삼각형 4개(인덱스 12개)를 내보내는 방식이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
bool render = (xlane == 7) ? false : true;
bool render1 = (xlane == 7) ? false : true;
if (ylane == 3) render1 = false;
//모두 레벨 0이면 삼각형 방출 안함
if (h1 < 1550 && h2 < 1550 && h1r < 1550 && h2r < 1550) {
render = false;
render1 = false;
}
uint vote = ballotThreadNV(render); //활성화 된 모든 쓰레드 표시
uint tasks = bitCount(vote); // 활성화 된 모든 쓰레드의 개수 세기
uint vote1 = ballotThreadNV(render1);
uint tasks1 = bitCount(vote1);
if (laneID == 0) {
gl_PrimitiveCountNV = tasks * 2 +tasks1 * 2; //하나당 4개씩
}
if (render) {
uint idx = bitCount(vote & gl_ThreadLtMaskNV); //and 연산을 통해 배열 번호를 계산한다.
for (int i = 0; i < 6; i++) {
gl_PrimitiveIndicesNV[idx * 6 + i] = (xlane *2 + ylane * 16 * 2) + offset[i];
}
}
if (render1) {
uint idx1 = bitCount(vote1 & gl_ThreadLtMaskNV); //and 연산을 통해 배열 번호를 계산한다. for (int i = 0; i < 6; i++) {
gl_PrimitiveIndicesNV[(tasks * 2 * 3) + (idx1 * 6 + i)] = (xlane * 2 + ylane * 16 * 2 + 16) + offset[i];
}
}
|
cs |
render1 부분에서 인덱스 번호를 매길 때, primitiveIndicesNV의 배열번호에 기본적으로 render부분의 개수를 모두 누적시킨 후 다음 번호를 부여했음에 유의해서 보자.
부가적인 내용 : meshlet 정보를 이용하기

위처럼 전체 삼각형을 인접한 삼각형들로 나눌 수 있다고 하자. 각각의 삼각형은 64개 정점을 기준으로 분할되어 정점 배열에 담긴다. 그 후에 태스크 쉐이더에서 메쉬렛의 한 점만 읽어서 안전 범위 내에서 frustum culling만을 해서 메쉬 셰이더로 보내기만 해도 GPU 계산 부담이 많이 줄어들게 된다.
그렇다면 태스크 쉐이더에서 읽어야 하는 정보는 기본적으로 이 정점이 담긴 데이터 이외에 메쉬렛 구조체로 된 데이터가 필요하게 된다. 메쉬렛 구조체는 일반적으로 다음의 네 가지 정보를 담는다. built-in 구조체가 아니며, 자유롭게 응용 가능하다.
|
1
2
3
4
5
6
|
struct MeshletDesc {
uint32_t vertexCount; // number of vertices used
uint32_t primCount; // number of primitives (triangles) used
uint32_t vertexBegin; // offset into vertexIndices
uint32_t indexBegin; //
};
|
cs |
일단 vertexBegin에는 기본정점배열 데이터에서 해당 메쉬렛이 몇 번 정점부터 시작하는지 정보를 넣어준다. 그래서 몇 개를 셀지는 vertexCount에 넣어준다. 이 두 값은 전통적 파이프라인에서 indirect 드로잉을 할 때 항상 쓰이는 값들이기도 하다.
3의 배수로 들어 있는 기본 버텍스 인덱스 배열도 메쉬 셰이더로 함께 보내야 하는데, primcount는 이와 관련한 정보가 들어간다. 해당 메쉬렛의 primitive 개수가 들어가도 되고, 아니면 그 3의 배수인 인덱스 개수가 들어가도 된다.
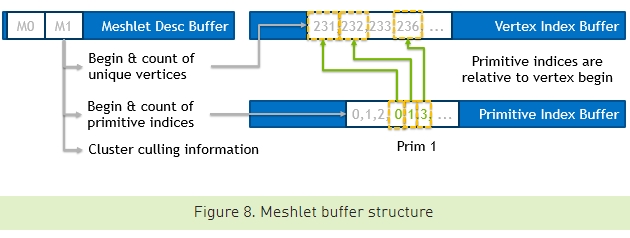
엔비디아 홈페이지에는 위의 그림과 같이 primitive index buffer도 별도로 두라고 말한다. 메쉬렛 당 255개 정점 이하가 필요할 것이므로 8비트 단위 정수 배열로도 충분하다. 이것을 어떻게 이용할지는 프로그래머에 달렸다.
일단 나는 다음과 같은 4개의 배열을 셰이더로 보냈다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
layout(binding = 0) buffer vertexBuffer {
VertexArray vertex[];
};
layout(binding = 1) buffer meshletVertexArrayBuffer {
uint meshletVertexArray[];
};
layout(binding = 2) buffer meshletIndexBuffer {
uint8_t meshletIndex[];
};
layout(binding = 3) buffer MeshletDescBuffer {
MeshletDesc meshletDesc[];
};
|
cs |
vertexBuffer는 xyz 3개 좌표가 담긴 정점 배열이다.
meshletVertexArrayBuffer은 vertexBuffer의 배열 번호를 가리키는 가장 기본적인 인덱스 버퍼다. 전처리를 통해 정점의 수가 62~64개가 될 때까지 삼각형들을 카운트해나가면서 meshletVertexArrayBuffer에 집어넣는다. 전처리를 할 때 std::set 에 집어넣으면서 누적시켜 중복을 제거한다. 지금 넣고 있는 set 안의 인덱스 값들은 set의 특성상 자체적으로 sort도 되어 있다. 중복을 제거하는 까닭은 어차피 다시 meshletIndex 에 넣는 인덱스를 통해 삼각형을 구성할 것이기 때문이다.
meshletVertexArrayBuffer에서는 한 메쉬렛과 다른 메쉬렛에서 일부 인덱스들이 중복될 수 있다.
meshletIndexBuffer는 meshletVertexArrayBuffer에 들어간 정점 그룹들만을 기준으로 인덱스 번호를 넣는다. triangle strip 방식이 아니므로 모든 삼각형 개수 x 3개의 많은 정보가 들어가지만 8비트 정수의 배열이므로 용량은 많이 줄어들게 된다. 그리고 엔비디아에서 강조하는, 캐시를 통한 'vertex-reuse'가 되기 때문에 strip 이 아님에도 불구하고 매우 빠르게 삼각형을 구성한다. 바로 이 캐시 한계 때문에 정점 64개와 프리미티브 126개라는 점을 앞서 설명한 바 있다.
다시 정리해보면, 이 경우 앞에서 설명한 MeshletDesc 구조체의 vertexcount와 vertexBegin에는 meshletVertexArrayBuffer에 대한 정보가 들어있다.
indexBegin과 primCount에는 meshletIndex에 대한 정보가 들어있는 셈이다. primeCount는 삼각형의 개수인데 어차피 3의 배수가 되므로 삼각형이 30개일 때 30을 쓰든, 인덱스 수인 90을 쓰든 결국 구현하는 과정에 달렸다.
이 두 버퍼의 값에서 최초 점 데이터의 인덱스를 계산해서 원시 정점 데이터에 접근하게 된다.
코드로 풀어보면 아래와 같다.
uint vertexIndex = meshletVertexArray[meshlet.vertexBegin + offset];
VertexArray vertex0 = vertex[vertexIndex];
gl_PrimitiveIndicesNV[offset] = uint(meshletIndex[meshlet.indexBegin + offset]);
그림으로 표현해보면 아래와 같다.

이와 관련된 MeshletDesc 를 구성한다면 아래와 같다.

기존의 시도들과 mesh shader
mesh shader 코드 작성에 대한 내용은 여기까지다.
그런데 mesh shdaer는 완전히 새로운 시도인가? 그렇지 않다. 사실, 자료들을 찾아보면 여러가지 렌더링 타임 최적화 방식들이 시도되었음을 알 수 있다. 아래의 글이 여러가지 개념을 잡는데 가장 많이 도움이 되었다.
https://frostbite-wp-prd.s3.amazonaws.com/wp-content/uploads/2016/03/29204330/GDC_2016_Compute.pdf
2016년 3월의 글인데, 이 자료를 읽어보면, 결국 이 글에서 시도한 내용과 같은 것들을 어떻게 하드웨어적으로 가장 잘 뒷받침할까를 고민하다가 전통적인 파이프라인을 대체하는 mesh shader 방식을 고안하게 된 것이 아닐까라는 생각도 든다.
이 글의 cluster culling 은 meshlet 과 아주 유사한 개념인 것 같고, 이미 이때 'draw compaction'을 위해 Nvidia의 shader thread group 확장이 제공되었다. 먼 곳의 삼각형이나 비슷한 이유로 아주 작아지는 삼각형 중 일부를 그리지 않는 small primitive culling 같은 경우, 내가 쓴 이 글에서는 다루지 못했는데, Nvidia 가 Turing Architecture에서 제공하는 프래그먼트 셰이더의 NV_fragment_shader_barycentric 확장 사양과 연관이 될 것 같다.
shader 코드 전체
설명은 여기까지다.
마지막으로, 앞에서 예로 든, 단순한 LOD 형식을 적용시켜 지형을 만드는 mesh shader 코드 전체를 올려본다.
사용한 데이터는 DEM 그리드 형식으로 25m 간격으로 높이(z좌표를 변형시킨 값)만 넣어놓았다. xy 좌표는 배열 번호를 통해 계산할 수 있다. 좌표를 복기하는 과정도 코드 안에 들어있다.
사실, 아래처럼 구현하면 시점에서 거리가 멀어지는 특정한 순간에 LOD 변경이 일어나 계단식으로 LOD가 축소된다. 그리 좋은 코드는 아니지만 메쉬 셰이더의 개념과 문법을 이해하는데는 충분할 것 같다.
우선 task shader
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
|
#version 460 core
#extension GL_NV_mesh_shader : require
#extension GL_NV_shader_thread_group : require
#extension GL_NV_gpu_shader5 : require
#define WARP_SIZE 32
#define GROUP_SIZE WARP_SIZE
#define M_PI 3.14159265358979323846
layout(local_size_x = GROUP_SIZE) in;
#define LANDX 25921
#define LANDY 24561
#define XBASE 741000
#define YBASE 1456000
#define TASKX 462
#define TASKY 877
#define TASKWIDTH 1400
#define TASKHEIGHT 700
#define MESHCELL 175
#define UNIT 25
uniform float scaleZ;
uniform vec4 margin;
uniform vec2 screen;
uniform mat4 PMV;
uniform mat4 Projection;
uniform mat4 View;
uniform vec4 frustumPlanes[6];
uint baseID = gl_WorkGroupID.x *GROUP_SIZE;
uint laneID = gl_LocalInvocationID.x;
uint wgID = gl_WorkGroupID.x;
//taskNV로 항상 output을 만든다. 이것은 mesh shader에서 접근 가능하다.
//이 데이터는 워크 그룹 안에서 공유한다. 그러므로 배열로 만들어주어야 한다.
taskNV out Task{
uvec4 cellID[GROUP_SIZE];
} OUT; //여기서 지정하는 수는 mesh shader와 반드시 맞아야 한다.
//코드를 작성한 후 1년 뒤에 생각해보니 굳이 이렇게 하지 않고 비트연산을 하면 더 나을 것 같다.
uniform bool lod2[32] = { true, false, true, false, true, false, true, false,
false, false, false, false, false, false, false, false,
true, false, true, false, true, false, true, false,
false, false, false, false, false, false, false, false };
uniform bool lod1[32] = { true, false, false, false, true, false, false, false,
false, false, false, false, false, false, false, false,
false, false, false, false, false, false, false, false,
false, false, false, false, false, false, false, false };
bool isInsideFrustum(uvec4 thisMargin)
{
bool result = true;
for (int i = 0; i < 6; i++) {
float dist = dot(frustumPlanes[i], vec4(thisMargin.xy, 0, 1));
if (dist < -4000) result = false;
}
return result;
}
void main()
{
//1400 x 700좌표 결정
uint ycoor = uint(wgID / TASKX);
uint xcoor = wgID - ycoor * TASKX;
//위 안에서 가로8 x 세로4 = 32 개 위치 결정
uint ylane = uint(laneID / 8);
uint xlane = laneID - ylane*8;
uvec2 thisbase = uvec2( XBASE + (xcoor * TASKWIDTH) + MESHCELL * xlane,
YBASE + (ycoor * TASKHEIGHT) + MESHCELL * ylane);
uvec4 thisMargin = uvec4(thisbase.x, thisbase.y, thisbase.x + MESHCELL, thisbase.y + MESHCELL);
//margin culling
bool render = isInsideFrustum(thisMargin);
vec4 point0 = PMV * vec4(XBASE + (xcoor * TASKWIDTH), YBASE + (ycoor * TASKHEIGHT), 0, 1);
vec4 point1 = PMV * vec4(XBASE + ((xcoor+1) * TASKWIDTH), YBASE + ((ycoor+1) * TASKHEIGHT), 0, 1);
float pixelWidth = length(screen * distance(point0.xy / point0.w, point1.xy / point1.w)*0.5);
if (pixelWidth < 70.0) {
render = (laneID == 0) ? render && true : false;
}
else if (pixelWidth < 100.0) {
render = render && lod1[laneID];
}
else if ( pixelWidth <200.0) {
render = render && lod2[laneID];
}
uint vote = ballotThreadNV(render); //활성화 된 모든 쓰레드 표시
uint tasks = bitCount(vote); // 활성화 된 모든 쓰레드의 개수 세기
if (laneID == 0) {
gl_TaskCountNV = tasks;
}
if (render) {
uint idxOffset = bitCount(vote & gl_ThreadLtMaskNV); //and 연산을 통해 배열 번호를 계산한다.
//cellID는 land의 배열번호에 사용할 것임
uint x = xcoor * (TASKWIDTH / UNIT) + xlane * 7;
uint y = ycoor * (TASKHEIGHT / UNIT) + ylane * 7;
if (pixelWidth < 70.0) {
OUT.cellID[idxOffset] = uvec4(x, y, 8, 4);
}
else if (pixelWidth < 100.0) {
OUT.cellID[idxOffset] = uvec4(x, y, 4,4);
}
else if (pixelWidth < 200.0) {
OUT.cellID[idxOffset] = uvec4(x, y, 2,2);
}
else {
OUT.cellID[idxOffset] = uvec4(x, y, 1,1);
}
}
}
|
cs |
그 다음으로 mesh shader
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
|
#version 460 core
#extension GL_NV_mesh_shader : require
#extension GL_NV_shader_thread_group : require
#extension GL_NV_gpu_shader5 : require
#define M_PI 3.14159265358979323846
#define LANDX 25921
#define LANDY 24561
#define XBASE 741000
#define YBASE 1456000
#define TASKX 462
#define TASKY 877
#define TASKWIDTH 1400
#define TASKHEIGHT 700
#define MESHCELL 175
#define WARP_SIZE 32
#define GROUP_SIZE WARP_SIZE
#define MAX_VERTICES 64
#define MAX_PRIM 126
struct LAND {
uint16_t x[LANDX];
};
layout(binding = 0) buffer landBuffer {
LAND land[];
};
layout(local_size_x = GROUP_SIZE) in;
layout(max_vertices = MAX_VERTICES, max_primitives = MAX_PRIM) out; //각각 max값
layout(triangles) out;
uniform float scaleZ;
uniform vec4 margin;
uniform vec2 screen;
uniform mat4 PMV;
uniform mat4 Projection;
uniform mat4 View;
uint laneID = gl_LocalInvocationID.x;
taskNV in Task {
uvec4 cellID[GROUP_SIZE];
} IN; //여기서 지정하는 수는 mesh shader와 반드시 맞아야 한다.
//LAND 데이터에 적용시킬 수 있는 번호 64개 버텍스 메쉬렛 단위다.가로세로 같은 크기로 설정(175X175)
uvec4 cellID = IN.cellID[gl_WorkGroupID.x];
perprimitiveNV out MESHOUT{
flat vec3 normal;
} meshout[];
uniform uint offset[6] = { 0,1,8, 9,8,1 };
uniform uint offset2[6] = { 0,1,2, 1,3,2 };
uint atomicIndex;
void main()
{
//현재 32개 쓰레드 안에서의 배분. 8X8 격자에서 할당한다.
uint ylane = uint(laneID / 8);
uint xlane = laneID - ylane * 8;
//LAND 데이터에 적용시킬 수 있는 좌표가 된다.
//x는 하나당 하나, y는 하나당 두 줄씩 배분. 64개 점을 32개 안에서 해결해야 함
uint xcoor = cellID.x + cellID.z * xlane; //0~7
uint ycoor = cellID.y + cellID.w * ylane * 2; //0,2,4,6
//점 하나와 그 위의 점(0번과 8번)
int h1 = int(land[ycoor].x[xcoor]);
int h2 = int(land[ycoor + (1 * cellID.w)].x[xcoor]);
float hh1 = float(h1 / 32.0) - 48.0;
float hh2 = float(h2 / 32.0) - 48.0;
vec3 vertex0 = vec3(XBASE + xcoor * 25, YBASE + ycoor * 25, hh1 * scaleZ);
vec3 vertex1 = vec3(XBASE + xcoor * 25, YBASE + (ycoor + (1* cellID.w)) * 25, hh2 * scaleZ);
//점 방출
gl_MeshVerticesNV[ylane * 8 * 2 + xlane].gl_Position = Projection * View * vec4(vertex0, 1.0);
gl_MeshVerticesNV[ylane * 8 * 2 + xlane + 8].gl_Position = Projection * View * vec4(vertex1, 1.0);
int h1r = 0;
int h2r = 0;
bool render = (xlane == 7) ? false : true;
bool render1 = (xlane == 7) ? false : true;
if (ylane == 3) render1 = false;
h1r = int(land[ycoor].x[xcoor + (1 * cellID.z)]);
h2r = int(land[ycoor + (1 * cellID.w)].x[xcoor + (1 * cellID.z)]);
//모두 레벨 0이면 삼각형 방출 안함
if (h1 < 1550 && h2 < 1550 && h1r < 1550 && h2r < 1550) {
render = false;
render1 = false;
}
uint vote = ballotThreadNV(render); //활성화 된 모든 쓰레드 표시
uint tasks = bitCount(vote); // 활성화 된 모든 쓰레드의 개수 세기
uint vote1 = ballotThreadNV(render1);
uint tasks1 = bitCount(vote1);
if (laneID == 0) {
gl_PrimitiveCountNV = tasks * 2 + tasks1 * 2; //하나당 4개씩
}
float hh1r = float(h1r / 32.0) - 48.0;
float hh2r = float(h2r / 32.0) - 48.0;
int h3 = int(land[ycoor + (2 * cellID.w)].x[xcoor]);
int h3r = int(land[ycoor + (2 * cellID.w)].x[xcoor + (1 * cellID.z)]);
float hh3 = float(h3 / 32.0) - 48.0;
float hh3r = float(h3r / 32.0) - 48.0;
vec3 vertex2 = vec3(XBASE + xcoor * 25, YBASE + (ycoor + (2 * cellID.w)) * 25, hh3 * scaleZ);
vec3 vertex3 = vec3(XBASE + (xcoor + (1 * cellID.z)) * 25, YBASE + ycoor * 25, hh1r * scaleZ);
vec3 vertex4 = vec3(XBASE + (xcoor + (1 * cellID.z)) * 25, YBASE + (ycoor + (1 * cellID.w)) * 25, hh2r * scaleZ);
vec3 vertex5 = vec3(XBASE + (xcoor + (1 * cellID.z)) * 25, YBASE + (ycoor + (2 * cellID.w)) * 25, hh3r * scaleZ);
vec3 normal0 = normalize(cross(vertex3 - vertex0, vertex1 - vertex0));
vec3 normal1 = normalize(cross(vertex1 - vertex4, vertex3 - vertex4));
vec3 normal2 = normalize(cross(vertex4 - vertex1, vertex2 - vertex1));
vec3 normal3 = normalize(cross(vertex2 - vertex5, vertex4 - vertex5));
if (render) {
uint idx = bitCount(vote & gl_ThreadLtMaskNV); //and 연산을 통해 배열 번호를 계산한다.
for (int i = 0; i < 6; i++) {
gl_PrimitiveIndicesNV[idx * 6 + i] = (xlane + ylane * 8 * 2) + offset[i];
}
meshout[idx * 2 + 0].normal = normal0;
meshout[idx * 2 + 1].normal = normal1;
}
if (render1) {
uint idx1 = bitCount(vote1 & gl_ThreadLtMaskNV); //and 연산을 통해 배열 번호를 계산한다.
for (int i = 0; i < 6; i++) {
gl_PrimitiveIndicesNV[(tasks * 2 * 3) + (idx1 * 6 + i)] = (xlane + ylane * 8 * 2) + offset[i] + 8;
}
meshout[(tasks * 2) + idx1 * 2 + 0].normal = normal2;
meshout[(tasks * 2) + idx1 * 2 + 1].normal = normal3;
}
}
|
cs |
마지막으로 fragment shader
이리저리 효과를 바꾸느라 고친 흔적이 남아 있다. fragment shader는 메쉬 셰이더 방식과 상관 없다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#version 460 core
#define M_PI 3.14159265358979323846
out vec4 o_FragColor;
uniform vec3 lightNormal = normalize(vec3(-0.5, -1.0, 2.0));
uniform vec4 lightColor = vec4(1.0, 1.0, 1.0,1.0);
uniform vec4 mainColor = vec4(15/255.0, 58/255.0, 41/255.0, 1);
in MESHOUT{
flat vec3 normal;
} colorin;
void main()
{
vec3 surfaceNormal = colorin.normal;
float cosT0 = dot(lightNormal, surfaceNormal)*0.5;//+ 0.5;
float cosT1 = dot(lightNormal, -surfaceNormal)*0.5;// + 0.5;
vec4 color1 = cosT0 > cosT1? cosT0 *cosT0 * lightColor : cosT1 *cosT1 * lightColor;
//vec3 color1 = cosT0 > cosT1 ? sin(cosT0*M_PI / 2) * lightColor : sin(cosT1*M_PI / 2) * lightColor;
vec4 color = mix(mainColor, color1, 0.7);
//vec4 color = mainColor * color1;
o_FragColor = 1-(1-color)*(1-color);
//o_FragColor = vec4(0.1,0.2,1.0,1.0);
// o_FragColor = colorin.color;
}
|
cs |
'Function' 카테고리의 다른 글
| 10만개의 수를 draw call 한번으로 그리기 (0) | 2020.12.18 |
|---|---|
| 통계청 집계구 인구를 격자로 재할당하기 (7) | 2020.12.15 |
| 데이터로서의 이미지 : 수백만개 선들의 적층과 재분해 (4) | 2020.04.25 |
| 국토교통부 실거래가 데이터 전처리 (10) | 2020.04.19 |
| 공시지가 - 전국 모든 땅의 가격은 얼마나 높고 낮은가? (1) | 2020.03.02 |



