
250만 음식점 데이터를 서버 없이 검색하기
페북에서 스크롤 몇 번만 해도 수십MB가 다운로드되는 요즈음이지만, 데이터 혹은 보여주어야 하는 컨텐츠가 많아질수록 되도록 기본 단위를 경량화시키는건 데이터로 운영되는 웹사이트 엔지니어링에서의 실용적 미덕과 같은 것이라 할 수 있다.
localdata.kr에서는 몇십년동안 신고되었던 일반음식점과 휴게음식점을 한번에 다운받을 수 있다. 250만건 정도 되는데 이름과 주소, 개폐업일 정도를 남기고 CSV로 저장하면 500MB 가까이 된다. 이런 규모의 데이터를 동적 서버 없이, GitHub Pages 같은 정적 저장 공간만으로 검색하고 지도 위에 보여줄 수 있을까?
하고 싶은 것
이 데이터로 해보고 싶은 것은 크게 두 가지다. 첫 번째는 텍스트 검색, 두 번째는 공간 검색이다. 그리고 도전 과제는 다음과 같다.
"텍스트 검색과 공간 검색을 어떻게 하나의 인덱스 체계로 엮을 것인가? 빠르게, 작은 용량으로."
이 글에서는 Roaring Bitmap과 quadkey tile index를 적용한 과정들을 설명해보려고 한다.
우선 텍스트 검색 부분부터 살펴보자.
텍스트 검색
음식점 이름에 "밀면"이 들어간 곳을 찾고 싶다. 개업 중인 곳만, 혹은 2010년 이후에 개업한 곳만 필터링하고 싶다. 즉, 음식점 이름, 영업상태, 개폐업연도 3개의 필드를 설정해본다.
그런데 몇백MB가 되는 250만 건을 전부 내려받아서 filter()를 돌릴 수는 없으니, 미리 "어떤 레코드가 조건에 해당하는가"를 압축된 인덱스로 만들어두고 필요한 인덱스만 받아서 교집합을 구하면 된다. 여기서 사용하는 기술이 바로 Roaring Bitmap 인덱스다.(뒤에서 좀 더 상세히 설명)
음식점 이름에 등장하는 고유 글자는 약 3,500개다. 이 글자 하나하나에 대해 "250만 레코드 중 이 글자를 포함하는 레코드는 어느 것인가"를 나타내는 250만 Bit(305KB)짜리 비트의 배열을 만든다. 그대로 저장하면 3,500 × 305KB ≈ 1GB가 되지만, Roaring Bitmap의 압축 덕분에 전부 합쳐서 27MB로 줄어든다. "점"처럼 43만 건에 등장하는 흔한 글자는 압축이 덜 되어 비트맵이 크고, 한두 번만 나타나는 희귀 글자는 대부분 0으로 구성되므로 자체 알고리즘으로 압축되면 몇 바이트 수준이다.
250만개 배열중에 등장하는 경우를 1로, 아닌 경우를 0으로 둔다는 근본 원칙은 같지만 음식점 이름, 영업 상태, 개폐업, 이 세 종류의 인덱스는 특성이 다르기 때문에 저장과 전달 방식 역시 각각 다르게 접근했다.
영업 상태 — 영업/폐업 두 가지뿐이므로 Roaring Bitmap 하나를 gzip 압축한 파일(open.roar.gz, 38KB)로 충분하다. 앱 시작 시 한 번 받으면 끝이다.
개업 연도 — 연도 수는 수십 개인데, 연도별로 .roar.gz를 만들면 파일이 연도 수 만큼 생성 된다. 물론 이걸 몇십번의 요청으로 받을 수는 없으니, 압축을 해서 받아야 한다. 그런데 그 후 클라이언트에서 활용하려면, 전체압축 풀기 → 인덱스 압축 풀기 → 인덱스 후처리 를 해야 한다. 그러므로 차라리 250만 행 × 연도 1컬럼짜리 parquet 파일(openyear.parquet, 2.3MB) 하나를 통째로 받고, 클라이언트에서 연도별 비트맵을 직접 생성하는 편이 낫다고 판단했다. 250만 행을 한 번 순회하면서 인덱스를 구축하는 시간 비용은 무시할 수준이기 때문이다.
글자 인덱스 — 3,500개 비트맵을 합치면 27MB(localdata_index_all.bin)다. 27MB가 요즘 기준으로 아주 큰 용량은 아니지만, 사용자가 검색도 하기 전에 한꺼번에 받게 하는 건 웹 트래픽의 건전성 면에서 좋지 않다. 그래서 3,500개 비트맵을 하나의 바이너리 파일로 이어붙여 두고, 검색할 때 입력한 글자의 비트맵만 HTTP Range Request로 부분 다운로드한다. "밀면"을 검색하면 "밀"과 "면" 두 개의 비트맵만 받으면 된다.
정리하면:
| 인덱스 | 파일 | 크기 | 전달 방식 | 이유 |
| 영업 상태 | open.roar.gz | 38KB | 초기 로딩 | 파일 1개, 용량 작음 |
| 개업 연도 | openyear.parquet | 2.3MB | 초기 로딩 | 1번 요청으로 받고 클라이언트에서 비트맵 생성 |
| 글자 검색 | localdata_index_all.gz | 27MB | Range Request | 검색 시 필요한 글자만 부분 다운로드 |
영업 상태 필터링은 다음과 같이 작동한다.

개업연도 필터링은 다음과 같이 작동한다.

이름 검색은 다음과 같이 작동한다.
핵심: 모든 비트맵은 같은 정렬 순서를 공유한다
이 구조가 작동하려면 한 가지 전제가 필요하다. 모든 비트맵의 N번째 비트가 같은 음식점을 가리켜야 한다는 것이다.
그러기 위해서는 250만 건의 데이터가 전처리 단계에서 quadkey(타일맵 격자 번호) 순으로 정렬되어야만 한다. 이 정렬된 순서가 모든 인덱스의 기준이 된다. 예시로 10건의 음식점을 보자:
인덱스 이름 영업상태 개업연도 위치(타일)
───── ─────────── ──────── ──────── ──────────
0 부산밀면 영업 2010 타일 A
1 밀면사랑 영업 2011 타일 A
2 해운대횟집 폐업 2005 타일 A
3 서면돈까스 영업 2018 타일 B
4 밀면나라 폐업 2010 타일 B
5 남포동밀면 영업 2015 타일 C
6 자갈치식당 영업 2008 타일 C
7 초량밀면 영업 2011 타일 C
8 영도횟집 폐업 2003 타일 C
9 태종대식당 영업 2019 타일 C
이 10건에 대해 각 조건별 비트맵이 만들어진다. N번째 비트는 항상 N번째 음식점이다:
인덱스: 0 1 2 3 4 5 6 7 8 9
[글자] "밀" 비트맵: 1 1 0 0 1 1 0 1 0 0
"면" 비트맵: 1 1 0 0 1 1 0 1 0 0
"밀"AND"면": 1 1 0 0 1 1 0 1 0 0 ← 이름에 "밀면" 포함
[상태] "영업" 비트맵: 1 1 0 1 0 1 1 1 0 1
[연도] 2010년 비트맵: 1 0 0 0 1 0 0 0 0 0
2011년 비트맵: 0 1 0 0 0 0 0 1 0 0
2010~2011 OR: 1 1 0 0 1 0 0 1 0 0 ← 2010~2011년 개업
[공간] 타일 A 비트맵: 1 1 1 0 0 0 0 0 0 0
타일 B 비트맵: 0 0 0 1 1 0 0 0 0 0
타일 C 비트맵: 0 0 0 0 0 1 1 1 1 1
이제 "밀면 + 영업 중 + 2010~2011년 개업 + 화면에 타일 A,C가 보임"을 검색하면:
① "밀면" 결과: 1 1 0 0 1 1 0 1 0 0
② AND 영업: 1 1 0 0 0 1 0 1 0 0
③ AND 2010~2011: 1 1 0 0 0 0 0 1 0 0
④ 타일A OR 타일C (화면범위): 1 1 1 0 0 1 1 1 1 1
⑤ AND 화면범위: 1 1 0 0 0 0 0 1 0 0
→ 최종 결과: 인덱스 0, 1, 7 → "부산밀면", "밀면사랑", "초량밀면"
모든 비트맵이 같은 정렬 순서의 같은 250만 건을 기준으로 만들어졌기 때문에, 어떤 조합의 필터든 AND/OR 비트 연산만으로 처리할 수 있다. 비트 연산이므로 250만 비트에 대해서도 밀리초 단위로 끝난다.
공간 검색과 quadkey
위 예시에서 타일 A, B, C가 나왔는데, 이 타일 번호에는 quadkey를 사용한다. Quadkey는 전세계 웹 지도의 줌 레벨과 x/y 타일번호를 하나의 숫자로 인코딩한 것인데, zoom level 14 기준으로 전국을 약 수만 개의 격자로 나눈다.

타일별 비트맵은 별도의 비트맵 파일로 저장하지 않는다. 대신 localdata_quadkey_index.csv.gz(56KB)에 "어떤 타일이 존재하고, 각 타일에 레코드가 몇 건인지"만 기록해둔다.
quadkey,length
3302211...,42
3302213...,118
...
데이터가 quadkey 순으로 정렬되어 있기 때문에, 같은 타일에 속하는 레코드들은 연속된 인덱스를 갖는다. 위 예시에서 타일 A의 레코드가 인덱스 0, 1, 2이고 타일 B가 3, 4인 것처럼. 그래서 CSV의 length를 순서대로 누적하면 각 타일의 비트맵 범위를 알 수 있다:
타일 3302211...: length=42 → 인덱스 0~41 → 비트맵의 0~41번 비트를 1로
타일 3302213...: length=118 → 인덱스 42~159 → 비트맵의 42~159번 비트를 1로
...
바다나 산처럼 데이터가 없는 타일은 CSV에 없으므로 자연스럽게 걸러진다. 이 CSV 하나가 타일 목록 + 비트맵 생성 정보를 겸하는 셈이다. 비트맵 자체는 이 CSV를 받은 클라이언트(브라우저)가 직접 생성한다.
14레벨 기준 쿼드키로 13레벨이나 상위 레벨을 만드는 것은 매우 간단하다. 인접한 타일 네 장이 합쳐져 상위 타일 한 장을 만드는 등, 규칙이 명확하고 계산이 단순하기 때문이다. 03121 타일의 1단계 상위 타일은 0312다. 끝의 한자리만 잘라내면 된다.
타일 안에 속한 업소 수는 다음과 같이 빠르게 계산된다.

설계의 핵심
정리하면, 이 구조의 핵심은 다음 네 가지다.
① 모든 인덱스가 같은 정렬 순서를 공유한다. 250만 건을 quadkey 순으로 한 번 정렬해두면, 그 순서가 글자 비트맵에도, 영업 상태 비트맵에도, 연도 비트맵에도, 타일 비트맵에도 동일하게 적용된다. 5번째 비트는 어떤 비트맵에서든 같은 음식점이다. 이 일관성이 없으면 비트 연산 자체가 불가능하다.
② 글자/상태/연도/공간 필터가 전부 비트 연산으로 통일된다. 서로 전혀 다른 성격의 필터 — 텍스트 매칭, 속성 필터, 시간 범위, 공간 범위 — 가 모두 같은 자료구조(Roaring Bitmap)의 AND/OR로 처리된다. 새로운 필터를 추가하고 싶으면 비트맵 하나만 더 만들면 된다.
③ quadkey 정렬 덕분에 타일 비트맵을 length 누적만으로 만들 수 있다. 데이터가 타일 순서로 정렬되어 있으므로 같은 타일의 레코드가 연속 인덱스를 갖는다. 타일당 레코드 수(length)만 알면 비트맵 범위가 정해지기 때문에, 56KB짜리 CSV 하나로 수만 개 타일의 공간 인덱스를 표현할 수 있다.
④ 인덱스의 인덱스의 인덱스 — 단계마다 최소한의 데이터만 받는다.
① 메타데이터 CSV — "밀"의 비트맵이 27MB 파일의 어디(offset)에서 얼마(length)만큼인지
↓ Range Request (수KB)
② 글자 비트맵 — "밀"이 포함된 레코드 번호들 (예: 1번, 7번, 15023번, ...)
↓ AND 교집합
③ 공간 비트맵 — 그 레코드가 화면에 보이는 타일에 속하는지
↓ 결과 인덱스
④ 파일 위치 — 레코드 15023번 → 15023 ÷ 5000 → localdata_000015000.parquet (5000개마다 끊음. 개당 약 250KB)
↓ 다운로드 (250KB)
⑤ 실제 데이터 — 이름, 주소, 좌표, 개업일 ...실제 데이터(⑤)에 도달하기까지 네 단계의 인덱스를 거친다. 각 단계에서 필요한 최소한만 받기 때문에, 250만 건 × 500MB의 원본 데이터를 전혀 다운로드하지 않고도 검색이 가능하다.
이 글에서는 이 각 단계를 만드는 과정과 사용하는 과정을 코드와 함께 정리한다.
1. 데이터 전처리
원본 데이터 로딩
공공데이터포털에서 받은 일반음식점과 휴게음식점 CSV를 합친다. 필요한 컬럼만 골라서 읽는다.
import geopandas as gpd
import numpy as np
import pandas as pd
source_folder = "X:/#DB_SET/전국_로컬데이터/전체데이터_20250422"
df0 = pd.read_csv(
f"{source_folder}/fulldata_07_24_04_P_일반음식점.csv",
encoding="utf-8",
usecols=[1, 3, 5, 10, 11, 18, 21, 25, 26, 27],
names=["cate", "sggcode", "opendate", "state", "closedate",
"addr", "name", "type", "x", "y"],
dtype={"cate": str, "sggcode": str, "opendate": str, "state": str,
"closedate": str, "addr": str, "name": str, "type": str,
"x": np.float64, "y": np.float64},
)
df1 = pd.read_csv(
f"{source_folder}/fulldata_07_24_05_P_휴게음식점.csv",
# 동일한 설정
...
)
df = pd.concat([df0, df1], ignore_index=True)좌표 변환과 날짜 인코딩
원본 좌표는 EPSG:5174(한국 중부원점)이므로 WGS84로 변환한다. 날짜는 문자열 대신 1950-01-01 기준 경과 일수를 int32로 저장한다. 이렇게 하면 parquet 압축 효율이 올라가고, 클라이언트에서 날짜 비교가 정수 비교로 바뀐다.
# 좌표 변환
df["geometry"] = gpd.points_from_xy(df["x"], df["y"])
gdf = gpd.GeoDataFrame(df, geometry="geometry", crs="EPSG:5174")
gdf = gdf.to_crs("EPSG:4326")
# 날짜 → 일수 인코딩
base_date = pd.to_datetime("1950-01-01")
df["opendate"] = pd.to_datetime(df["opendate"], errors="coerce")
df["closedate"] = pd.to_datetime(df["closedate"], errors="coerce")
df["opendate_days"] = (df["opendate"] - base_date).dt.days.astype("int32")
df["closedate_days"] = (df["closedate"] - base_date).dt.days.astype("int32")
df["open_year"] = df["opendate"].dt.year.astype("int32")Quadkey 생성과 정렬
모든 레코드에 zoom level 14 기준의 quadkey를 부여한다. quadkey는 일반적으로 문자열("0213012...")로 표현하지만, 여기서는 int64로 인코딩한다. quadkey가 02131 이라면 이진수로 00 10 01 11 01 이렇게 각 자리수마다 2bit로 표현 가능하다. 그리고 맨 앞에(좌측에) 3(이진수 11)을 prefix로 붙여서 앞자리가 "0", "00" 같은 쿼드키일때 자리수가 줄어드는 것을 방지한다. (0013과 013 혹은 13을 서로 구분)
import mercantile
def tile_to_quadkey_int64(z, x, y):
quadkey_int64 = 3 # prefix 11 (binary)
for i in reversed(range(z)):
digit = ((y >> i) & 1) << 1 | ((x >> i) & 1)
quadkey_int64 = (quadkey_int64 << 2) | digit
return quadkey_int64
def lonlatzoom_to_tileid(lon, lat, zoom):
tile = mercantile.tile(lon, lat, zoom)
return tile_to_quadkey_int64(zoom, tile.x, tile.y)
gdf["quadkey"] = [lonlatzoom_to_tileid(x, y, 14) for x, y in zip(lon, lat)]
이렇게 quadkey를 부여한 후 quadkey → state → name 순서로 정렬하고 인덱스를 리셋한다. 이 정렬 순서가 중요한데, 같은 타일 안의 데이터가 연속된 인덱스를 갖게 되어 나중에 비트맵 압축률이 높아진다. 물론 정렬 순서에서 쿼드키가 가장 앞에 와야 함은
gdf.sort_values(by=["quadkey", "state", "name"], inplace=True)
gdf.reset_index(drop=True, inplace=True)
gdf["index"] = gdf.indexParquet 분할 저장
정렬된 데이터를 5000건씩 잘라서 parquet 파일로 저장한다. 파일명에 시작 인덱스를 넣어두면 나중에 클라이언트에서 레코드 번호만으로 어떤 파일을 받아야 하는지 바로 지정할 수 있다.
gdf["coord"] = list(zip(gdf.geometry.x, gdf.geometry.y))
gdf_sub = gdf[["index", "cate", "sggcode", "state", "type", "addr",
"name", "sido", "opendate_days", "closedate_days",
"quadkey", "coord"]]
chunk_size = 5000
for i in range(0, len(gdf_sub), chunk_size):
gdf_sub[i:i+chunk_size].to_parquet(
f"localdata_{i:09d}.parquet", index=False
)약 250만 건이므로 약 480개의 parquet 파일이 만들어진다. 각각 250KB 내외.
2. 인덱스 생성
글자별 Roaring Bitmap 인덱스
음식점 이름으로 검색하려면 "이 글자를 포함하는 레코드는 어떤 것들인가"를 빠르게 알아야 한다. 여기서 사용한 것이 Roaring Bitmap이다.
비트맵(bitmap)은 "250만 개 레코드 중 어떤 것이 조건에 해당하는가"를 0과 1의 나열로 표현하는 자료구조다. 예를 들어 "점"이라는 글자를 포함하는 레코드가 0번, 3번, 7번이라면 [1,0,0,1,0,0,0,1,...]이 된다. 이 방식의 장점은 두 조건의 교집합(AND)이나 합집합(OR)을 비트 연산으로 한번에 처리할 수 있다는 것이다.
다만 250만 비트를 그냥 저장하면 약 300KB인데, 대부분의 비트가 0인 희소(sparse) 비트맵에서는 낭비가 크다. Roaring Bitmap은 이 문제를 해결하기 위해 데이터를 65,536개 단위의 청크로 나누고, 각 청크의 밀도에 따라 배열, 비트셋, run-length encoding 중 가장 효율적인 방식을 자동으로 선택해서 압축한다. Elasticsearch, Apache Druid, ClickHouse 같은 검색·분석 엔진 내부에서 널리 쓰이는 기술이다.
이 프로젝트에서는 각 글자에 대해 "이 글자가 이름에 포함된 레코드"를 Roaring Bitmap으로 만들고, 검색 시 글자별 비트맵의 AND 교집합을 구하는 방식으로 사용했다.
먼저 음식점 이름에 등장하는 모든 글자를 추출한다.
unique_chars = list(set(''.join(gdf["name"].astype(str))))
unique_chars = [c for c in unique_chars if c != " "]
# → 약 3,500개 글자
각 글자에 대해 "이 글자가 이름에 포함된 레코드들의 인덱스"를 뽑아서 Roaring Bitmap으로 만든다. 여기서 주의할 점은, 같은 이름 안에 같은 글자가 여러 번 나와도 한 번만 세야 한다는 것이다.
from pyroaring import BitMap
import gzip
# 이름을 글자 단위로 분해 (중복 제거)
df_chars = gdf[["name", "index"]].copy()
df_chars["char"] = df_chars["name"].astype(str).apply(lambda x: list(set(x)))
df_exploded = df_chars.explode("char")
df_exploded = df_exploded.drop_duplicates(subset=["index", "name", "char"])
# 글자별 빈도 계산 → 빈도순 정렬
df_counts = df_exploded.groupby("char").size().reset_index(name="count")
df_counts = df_counts.sort_values(by="count", ascending=False).reset_index(drop=True)
df_counts["char_index"] = df_counts.index
# 글자별 Roaring Bitmap 생성 → gzip 압축 → 개별 파일 저장
df_merged = df_exploded.merge(df_counts, on="char", how="left")
df_merged = df_merged.sort_values(by=["char_index", "index"])
for i, (char, group) in enumerate(df_merged.groupby("char", sort=False)):
indices = group["index"].values
bitmap = BitMap(indices)
data = bitmap.serialize()
compressed = gzip.compress(data)
with open(f"indexgz/{i:06d}.roar.gz", "wb") as f:
f.write(compressed)
가장 많이 등장하는 글자는 "점"(435,581건), "식"(311,642건) 순이다.
하나의 바이너리로 번들링
글자가 3,500개이므로 파일도 3,500개가 된다. GitHub 저장소에서 자잘한 파일을 수천 개 호스팅하면 느려지기 때문에, 모든 gzip 파일을 하나로 이어붙이고 각 글자의 offset과 length를 메타데이터 CSV에 기록한다. 그게 바로 인덱스가 된다.
index_all = b""
df_counts["offset"] = 0
df_counts["length"] = 0
for i in range(len(df_counts)):
with open(f"indexgz/{i:06d}.roar.gz", "rb") as f:
data = f.read()
df_counts.loc[i, "offset"] = len(index_all)
df_counts.loc[i, "length"] = len(data)
index_all += data
# 번들 파일 저장 (약 27MB)
with open("localdata_index_all.bin", "wb") as f:
f.write(index_all)
# 메타데이터 CSV 저장
df_counts[["char", "length"]].to_csv("localdata_char_info.csv", index=False)
결과물은 이렇게 생겼다:
| char | count | offset | length |
|---|---|---|---|
| 점 | 435,581 | 0 | 225,070 |
| 식 | 311,642 | 225,070 | 186,297 |
| 이 | 302,642 | 411,367 | 185,606 |
| ... | ... | ... | ... |
클라이언트에서는 페이지 로딩 시 이 CSV를 내려받아 읽고, 원하는 글자의 offset/length로 localdata_index_all.bin에 HTTP Range Request를 보내면 된다. 27MB 전체를 받을 필요 없이 해당 글자의 비트맵만 수~수백KB를 받는다.
개폐업·연도 인덱스
영업 상태도 마찬가지로 Roaring Bitmap으로 만든다.
for state, group in gdf.groupby("state", sort=False):
indices = group["index"].values
bitmap = BitMap(indices)
compressed = gzip.compress(bitmap.serialize())
with open(f"{state}.roar.gz", "wb") as f:
f.write(compressed)개업 연도는 Parquet으로 저장한다. 클라이언트에서 parquet-wasm으로 바로 파싱하여 연도별 비트맵을 만든다. parquet으로 만들어서 받는 이유는 글의 서두에서 설명했다. 미리 만들어두는 것보다 클라이언트에서 구축하는게 효율적이기 때문이다.
gdf[["open_year"]].to_parquet("openyear.parquet", index=False)3. 프론트엔드: 데이터 로딩
초기화
앱이 시작되면 네 가지 인덱스를 로딩한다.
Quadkey 인덱스 — gzip 압축된 CSV를 받아서 각 타일별로 Roaring Bitmap을 생성한다. 이 비트맵은 "이 타일 안에 어떤 레코드들이 있는가"를 나타낸다.
// MapContext.tsx
async function initQuadkeyIndex(setAllDataSize) {
const response = await fetch("./localdata_quadkey_index.csv.gz");
const gzBuffer = await response.arrayBuffer();
const decodedData = pako.inflate(new Uint8Array(gzBuffer));
const csvText = new TextDecoder().decode(decodedData);
const result = parse(csvText, { header: true });
const quadkeyMap = new Map<bigint, QuadkeyIndex>();
let currentOffset = 0;
result.forEach((row) => {
const quadkey = BigInt(row.quadkey);
const length = parseInt(row.length);
const bitmap = new RoaringBitmap32();
for (let i = 0; i < length; i++) {
bitmap.add(currentOffset + i);
}
quadkeyMap.set(quadkey, { quadkey, bitmap });
currentOffset += length;
});
setAllDataSize(currentOffset); // 약 250만
return quadkeyMap;
}
데이터가 quadkey 순으로 정렬되어 있기 때문에, CSV에서 각 타일의 레코드 수(length)만 읽으면 연속된 인덱스 범위로 비트맵을 만들 수 있다. 이것이 앞서 정렬을 해둔 이유다.
로딩 후에는 상위 줌 레벨(z=7~13)의 부모 타일 비트맵을 계층적으로 생성한다. 하위 타일들의 비트맵을 OR 합집합하면 된다.
// MapContext.tsx
function generateUpperQuadkeyIndex(quadkeyMap) {
for (const [q14, quadkeyIndex] of quadkeyMap.entries()) {
for (let z = 13; z >= 7; z--) {
const shift = BigInt((14 - z) * 2);
const parentQuadkey = q14 >> shift;
const parent = expandedQuadkeyMap.get(parentQuadkey);
if (parent) {
parent.bitmap.orInPlace(quadkeyIndex.bitmap);
} else {
expandedQuadkeyMap.set(parentQuadkey, {
quadkey: parentQuadkey,
bitmap: quadkeyIndex.bitmap.clone(),
});
}
}
}
}
글자 인덱스 메타데이터 — CSV를 읽어서 글자→offset/length 맵을 만든다.
// searchByNameFunc.ts
export async function initCharIndex() {
const response = await fetch("./localdata_char_info.csv");
const csvText = await response.text();
const result = parse(csvText, { header: true });
const charMap = new Map<string, CharIndex>();
let currentOffset = 0;
for (let idx = 0; idx < result.length; idx++) {
const row = result[idx];
const length = parseInt(row.length);
charMap.set(row.char, {
index: idx,
char: row.char,
offset: currentOffset,
length,
});
currentOffset += length;
}
return charMap;
}검색: Range Request와 비트맵 교집합
사용자가 검색어를 입력하면 글자 단위로 분해해서 각각의 비트맵을 가져온다. 핵심은 fetchIndex() 함수다:
// searchByNameFunc.ts
async function fetchIndex(offset: number, length: number) {
const response = await fetch("./localdata_index_all.bin", {
headers: {
Range: `bytes=${offset}-${offset + length - 1}`,
},
});
const gzBuffer = await response.arrayBuffer();
const decodedData = pako.inflate(new Uint8Array(gzBuffer));
const bitmap = RoaringBitmap32.deserialize(decodedData, "portable");
return bitmap;
}
HTTP Range 헤더로 27MB 파일의 특정 바이트 범위만 요청한다. 예를 들어 "밀"이라는 글자의 offset이 1,234,567이고 length가 8,901이면, bytes=1234567-1243467만 받는다. GitHub Pages나 대부분의 CDN은 Range Request를 지원한다.
받아온 비트맵은 캐싱해서 같은 글자를 다시 요청하지 않는다. 영문 검색은 대소문자를 모두 가져와서 OR 합집합한 뒤, 모든 글자의 비트맵을 AND 교집합한다.
// searchByNameFunc.ts — searchChar()
export async function searchChar(value, charIndex, ...) {
const bitmapArr: RoaringBitmap32[] = [];
for (const char of value.trim()) {
const bitmap = await getBitMapOfChar(char, charIndex, bitmapRef);
if (bitmap) bitmapArr.push(bitmap);
}
// 모든 글자 비트맵의 교집합
const result = bitmapArr[0].clone();
for (let i = 1; i < bitmapArr.length; i++) {
result.andInPlace(bitmapArr[i]);
}
setSearchResult(result);
}
"밀면"을 검색하면 "밀" 비트맵과 "면" 비트맵의 교집합이 결과가 된다. Roaring Bitmap의 AND 연산은 250만 비트에 대해서도 밀리초 단위로 끝난다.
결과에서 Parquet 청크 다운로드
비트맵 교집합으로 나온 인덱스 배열에서, 각 인덱스가 어떤 5000건 청크에 속하는지 계산한다.
// searchByNameFunc.ts
export function getLocalDataFilename(bitmapArr: number[]) {
const filenameSet = new Set<number>();
for (const idx of bitmapArr) {
const fileIndex = Math.floor(idx / 5000) * 5000;
filenameSet.add(fileIndex);
}
return Array.from(filenameSet).sort((a, b) => a - b);
}
인덱스 12,345는 localdata_000010000.parquet에, 인덱스 250,001은 localdata_000250000.parquet에 들어있다. 필요한 파일만 받고, 이미 받은 파일은 캐시에서 꺼낸다.
// searchByNameFunc.ts
export async function getLocalDataFileMap(filenameArr, localDataFileMapRef) {
for (const filename of filenameArr) {
if (localDataFileMapRef.current.has(filename)) continue;
localDataFileMapRef.current.set(filename, []); // 중복 요청 방지
const data = await loadLocalDataFile(filename);
localDataFileMapRef.current.set(filename, data);
}
return localDataFileMapRef.current;
}
Parquet 파일은 parquet-wasm으로 파싱한다. 날짜는 저장된 일수에서 다시 Date 객체로 복원하고, 좌표는 Arrow Vector 구조에서 [lon, lat] 배열로 변환한다.
// GeoParquet.ts
static async readParquetToJsonCustom(url, setLocalDataDownloaded) {
const resp = await fetch(url);
const parquetUint8Array = new Uint8Array(await resp.arrayBuffer());
const arrowWasmTable = GeoParquet.parquet.readParquet(parquetUint8Array);
const table = tableFromIPC(arrowWasmTable.intoIPCStream());
const data: LocalData[] = new Array(table.numRows);
for (const row of table) {
const opendate = new Date(
basedate.getTime() + row.opendate_days * 86400000
);
const coordConverted = [
row.coord.data[0].values[0],
row.coord.data[0].values[1],
] as [number, number];
data[rowIndex++] = {
...row, coord: coordConverted, opendate, closedate, openyear, closeyear,
};
}
return data;
}4. 지도 시각화
타일 기반 공간 필터링
지도를 움직이면 현재 화면에 보이는 타일 목록을 계산한다. Deck.GL의 WebMercatorViewport에서 경위도 범위를 가져오고, 현재 줌 레벨에 해당하는 타일 좌표로 변환한다.
// tile.ts
export function refreshTileNumOnScreen(viewState, tileIndex, adjustZoom = 0) {
let { zoom } = viewState;
zoom = Math.floor(Math.max(Math.min(14, zoom + adjustZoom), 7));
const viewport = new WebMercatorViewport(viewState);
const [west, south, east, north] = viewport.getBounds();
const scale = Math.pow(2, zoom);
const { x: minX, y: maxY } = worldToTile(west, south, scale);
const { x: maxX, y: minY } = worldToTile(east, north, scale);
const tileArr: bigint[] = [];
for (let x = minX; x <= maxX; x++) {
for (let y = minY; y <= maxY; y++) {
const quadkey = tileToQuadkeyInt64(zoom, x, y);
if (tileIndex.has(quadkey)) tileArr.push(quadkey);
}
}
return tileArr;
}
화면 안의 타일들이 가진 비트맵을 모두 OR 합집합하면 "화면에 보이는 레코드들"의 비트맵이 된다.
// tile.ts
export function getBitmapOnScreen(tileArr, tileIndex) {
const bitmapOnScreen = new RoaringBitmap32();
for (const quadkey of tileArr) {
bitmapOnScreen.orInPlace(tileIndex.get(quadkey)!.bitmap);
}
return bitmapOnScreen;
}
검색 결과 비트맵과 화면 비트맵의 AND 교집합으로 "화면에 보이는 검색 결과"를 구한다. 추가로 영업 상태 필터, 연도 범위 필터도 각각의 비트맵과 AND 연산으로 적용된다. 모든 필터링이 비트 연산이므로 생각보다 굉장히 빠르다.
Deck.GL 레이어
줌 레벨에 따라 두 가지 방식으로 결과를 보여준다.
줌 아웃 (격자 표시) — 타일별로 검색 결과 수를 세서 노란색 격자로 표시한다. 투명도가 결과 수에 비례하므로 밀집 지역이 진하게 보인다. '밀면'을 치면 부산 쪽 격자가 가장 진하게 나타난다.
// DeckLayers.tsx
const tileResultLayer = new QuadkeyLayer({
id: "tile-result-quadkey",
data: tileArrOfResult,
getQuadkey: (d) => d.quadkey,
getFillColor: (d) => [255, 180, 0, (d.count / d.maxCount) * 150],
getLineColor: (d) => [255, 180, 0, 255],
getLineWidth: 2,
lineWidthUnits: "pixels",
filled: fillOn,
});
줌 인 (개별 점) — 결과 수가 화면에서 볼 만한 양이 되면 parquet 청크를 받아서 빨간 점으로 표시한다. 영업 중이면 빨강, 폐업이면 회색이다.
// DeckLayers.tsx
const scatterPlotLayer = new ScatterplotLayer({
id: "local-data-scatterplot",
data,
getPosition: (d) => d.coord,
getFillColor: (d) => {
if (d.state == "영업") return [255, 25, 0];
else return [50, 100, 150];
},
getRadius: 8,
radiusUnits: "pixels",
pickable: true,
});
같은 좌표에 여러 음식점이 겹치는 경우가 많다 (같은 건물에 식당이 여러 개). 이럴 때는 나선형으로 살짝 벌려서 배치한다.
// GeoParquet.ts
function adjustOverlappingPoints(key, data) {
let r = 0.00008; // 약 5m
let angle = 0;
for (let i = 0; i < data.length; i++) {
const dx = r * Math.cos(angle);
const dy = r * Math.sin(angle);
const dlon = dx / Math.cos((lat * Math.PI) / 180);
adjustedData.push({
...data[i],
coord: [lon + dlon, lat + dy],
angle,
r,
});
r += Math.max(0.000005 - 0.00000004 * i, 0.000002);
angle += 0.1 * (0.001 / (0.0002 + 0.000008 * i));
}
}여기까지 원리와 주요한 코드들을 설명했다. 다시 한 번 전체 데이터의 흐름을 정리하면 아래와 같다.
5. 전체 데이터 흐름
CSV 원본 (250만건, ~500MB)
│
▼
[전처리] 좌표 변환 · 날짜 인코딩 · quadkey 부여 · 정렬
│
├──▶ Parquet 청크 (5000건씩, ~480개 파일)
│ ↳ 클라이언트가 필요한 청크만 다운로드
│
├──▶ 글자별 Roaring Bitmap → gzip → 하나로 번들링 (27MB)
│ ↳ 메타데이터 CSV (글자·offset·length)
│ ↳ Range Request로 글자별 비트맵만 부분 다운로드
│
├──▶ 개폐업 Roaring Bitmap (open.roar.gz, 38KB)
│
├──▶ 개업연도 parquet (openyear.parquet, 2.3MB)
│
└──▶ Quadkey 인덱스 CSV (56KB, gzip)
클라이언트 (브라우저)
│
├── [초기화] quadkey 인덱스 + 글자 메타 + 상태 비트맵 + 연도 인덱스
│
├── [검색] 글자 입력 → Range Request → 비트맵 교집합
│
├── [필터] 화면 범위 AND · 영업 상태 AND · 연도 범위 AND
│
├── [줌 아웃] 타일별 카운트 → 노란 격자 (QuadkeyLayer)
│
└── [줌 인] Parquet 청크 다운로드 → 빨간 점 (ScatterplotLayer)demo
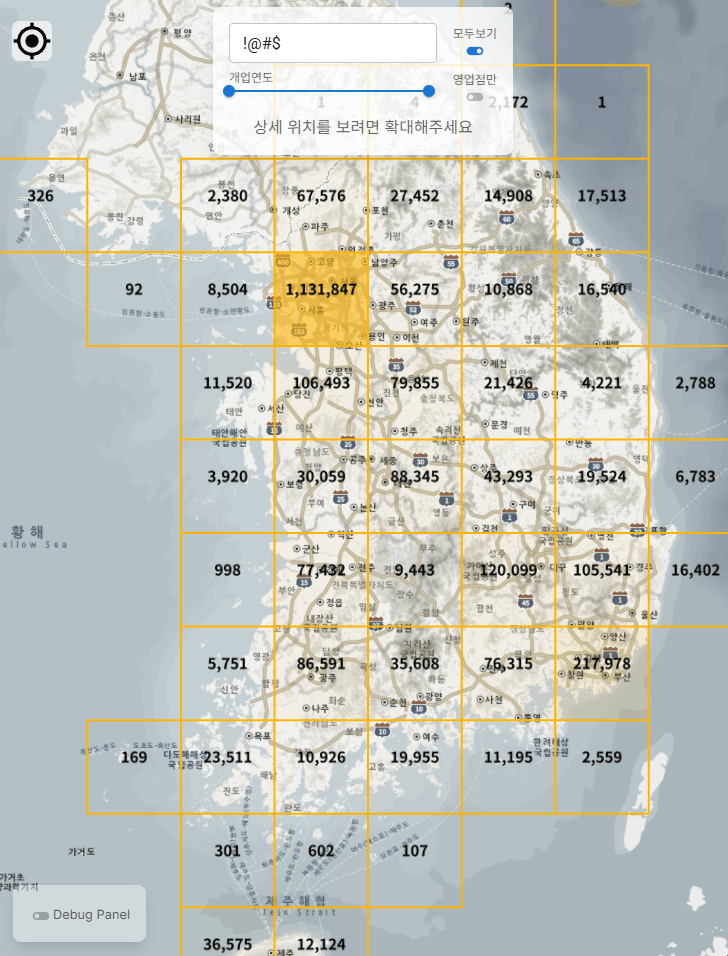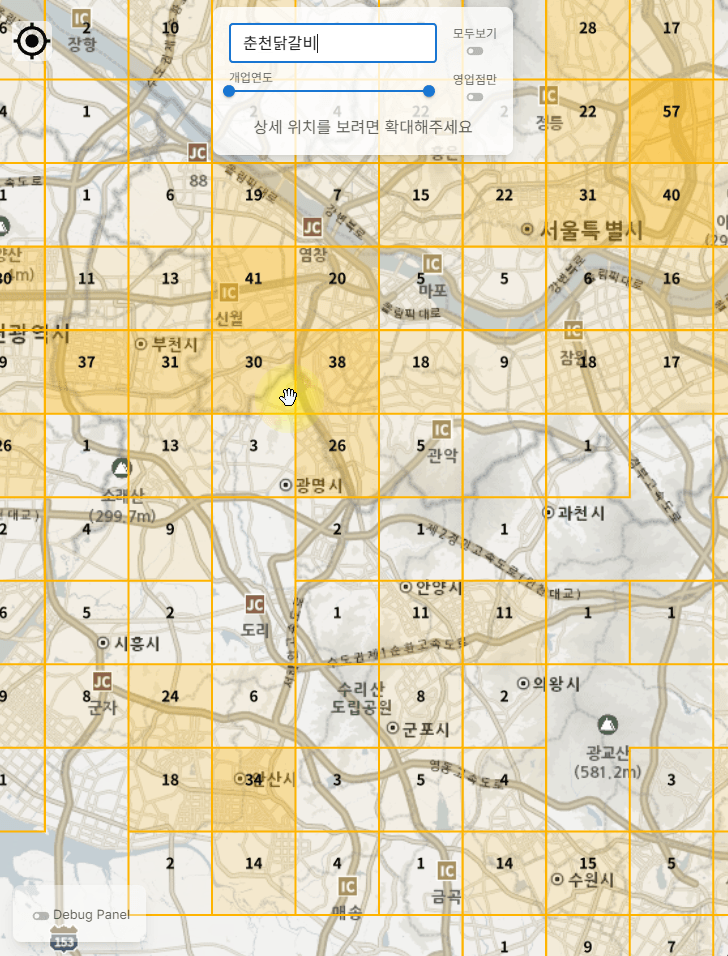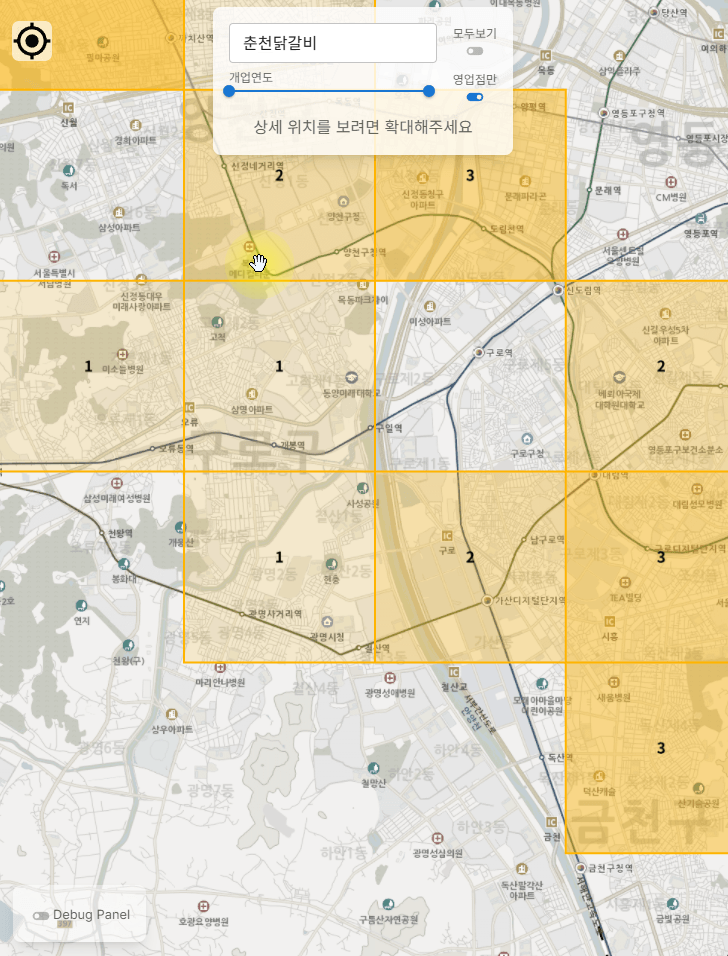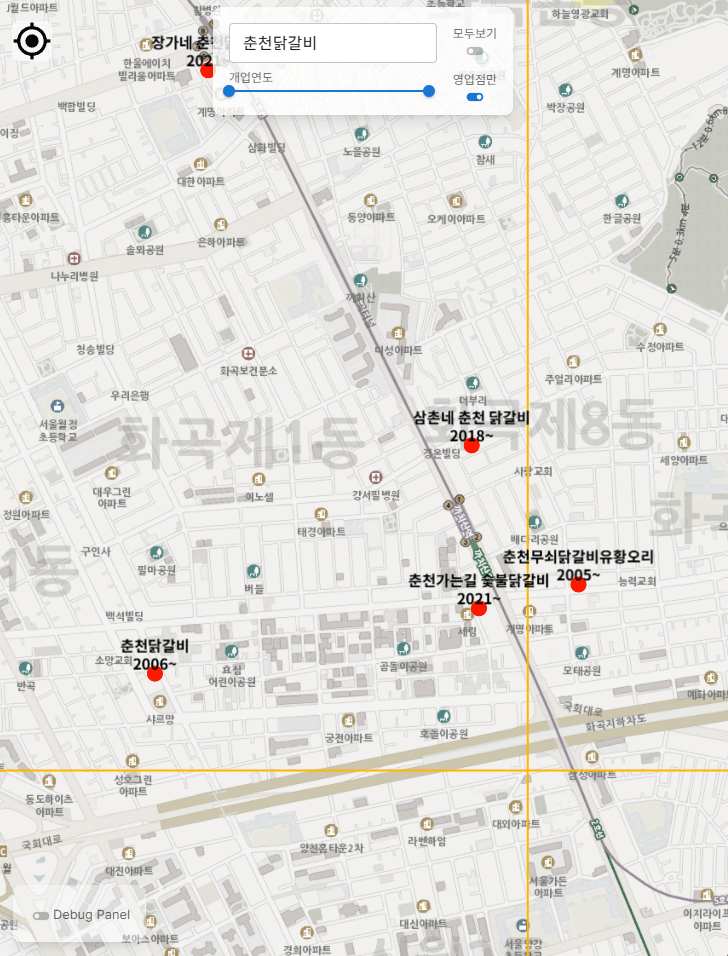
앞 서 각각의 예시를 gif로 보았지만, 다시 복합적인 조건으로 브라우징 해 볼 수 있다.

마무리
초기 로딩에 필요한 데이터는 quadkey 인덱스(56KB) + 글자 메타데이터(31KB) + 영업 상태 비트맵(38KB) + 연도 인덱스(2.3MB)를 합쳐서 약 2.5MB 정도다. 27MB짜리 글자 인덱스 파일은 통째로 받는 게 아니라 검색할 때 해당 글자의 비트맵만 Range Request로 수~수백KB씩 받고, 한 번 받은 비트맵은 캐싱되므로 검색을 반복할수록 네트워크 요청이 줄어든다. 요즘 LLM 스트리밍 한 번에 수초씩 연결이 열려있고 SNS 피드 스크롤에 수십MB가 오가는 것에 비하면, 이 정도 네트워크 비용은 사용자가 인지하기 어려운 수준이다.
250만 건 규모에서는 서버 없이도 충분히 실용적으로 작동한다. 서버 운영 비용이 0이라는 점도 개인 프로젝트에서는 큰 장점이다. 다만 1000만 건을 넘어가면 개별 비트맵의 크기가 커지고 브라우저의 메모리 부담이 늘어나므로, 그 규모에서는 서버사이드 인덱싱이나 DuckDB-WASM 같은 클라이언트 내 쿼리 엔진을 함께 고려해야 할 것이다.
딱히 특정한 컨텐츠 성격의 목적이 있어서 만든 사이트는 아니지만, 눈 앞에 보이는 음식점이 몇년도에 개업한 곳인지 찾아볼 수 있다. 이름에 '호프'가 들어간 주점들은 이제 많이 사라졌는데, 희한하게 남구로역 근처에는 아직도 많다.
아래에서 직접 해볼 수 있다.
로컬데이터(음식점) 찾기
로컬데이터(음식점) 찾기
localdata.vw-lab.com
사용 기술: Roaring Bitmap (roaring-wasm), Apache Arrow, Parquet (parquet-wasm, hyparquet), pako (gzip), Deck.GL,
'Function' 카테고리의 다른 글
| Flowring : 인구 이동 시각화와 행정구역 데이터의 시계열 정합성 (0) | 2026.04.03 |
|---|---|
| 1.7MB에 전국 100m 격자 인구 데이터 넣기 (0) | 2026.03.27 |
| OpenStreetMap과 GTFS 데이터를 이용한 도시 자원 접근성 분석 방법 (2) | 2025.03.27 |
| 전세계 기온 시각화 (2) | 2024.12.02 |
| OD 시각화 6 : OD 시각화 프로토타입 (1) | 2024.10.31 |



