
매 해마다 태어나는 아이들이 점점 줄어들어가는 우리나라는 매우 급격한 고령화의 한 가운데에 있다.
통계청의 인구 중위 추계에 따르면, 2070년의 연령별 남녀 인구는 아래 그림처럼 된다고 한다.

각각의 막대는 5세 인구 구간이고, 좌측이 남성, 우측이 여성이다.
가장 많은 인구 구간은 75~79세. 그러니까 1991년~1996년에 태어난 사람들이 2070년에 다다르면 70대의 노년층이 되어 우리나라에서 가장 흔한 나이대가 된다. 그래프에서 볼 수 있듯이 75세에서 젊어질수록 인구는 대체로 점차 줄어든다.
그렇다면 2023년 현재의 인구 분포는 어떨까?
(2020년에 예측한 2023년의 중위 추계 인구를 사용했다. 현재와 크게 다르지 않다.)
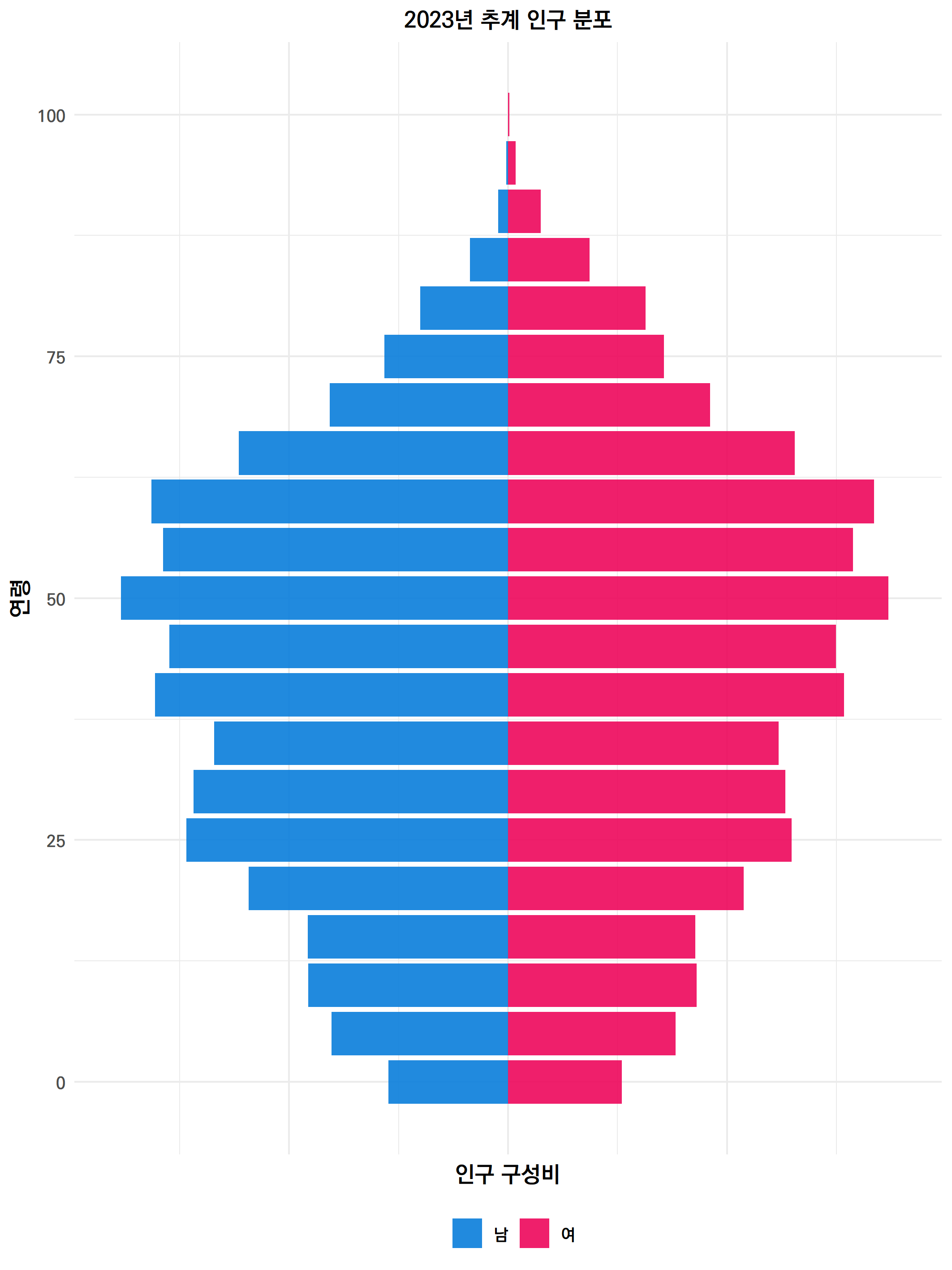
사실 현재의 인구 분포도 그다지 건강해보이지 않는다, 50~55세가 가장 많다. 이미 인구는 젊어질수록 줄어드는 형상을 보인다. 그래도 지금은 25세~50세가 고르게 두텁다.
그런데 사실 문제는 지금도 심각하다. 저런 분포의 인구가 전국에 고르게 흩어져 살지 않기 때문이다.
읍면동 단위의 인구 분포로 보자. 서울 중 150개를 끊어봤다.

각각이 다 다르다. 20대가 유난히 튀어나온 곳은 대부분 대학이 있는 동이다.그래도 서울은 20대 이하가 많은 편이다.
어린 인구가 많은 곳으로 치면 세종시가 제일이다.

도시가 새로 만들어지면서 어린 자녀가 있는 젊은 가족이 이사를 간 것 같다. 아니면 이주해서 낳았거나. 그런데 세종시 분포도 독특하다. 대학이 없기 때문에 20대가 허리처럼 잘록하게 들어가 있다. 그리고, 신도시가 아닌 연서면, 전의면, 전동면 같은 지역들은 역피라미드 형태를 띤다.
그러면 이번에는 경상북도를 볼까.

40대 이하가 심각하게 바싹 말라 있는 지역들이 많이 보인다.
그래서 한번 찾아봤다. 2070년의 우리나라 인구 분포는 전국 3500여개 읍면동 중 어디에 이미 존재하는 것이 아닐까?
분포의 유사성을 측정할 수 있는 와서스타인 거리(Wasserstein distance)로 2070년의 남녀 인구분포 42개 구간과 3500여개 읍면동 인구 분포의 거리를 계산해봤다. (와서스타인 거리는 분포 전체가 이동해 있는 형상에서의 유사성을 측정하는데 주로 쓰이는 것 같기도 한데, 그냥 구간별 차이를 제곱한 합계로도 계산해보니 결과가 크게 다르지 않아, 기왕이면 알려져 있는 척도를 사용하기로 했다)
그래서 가장 유사한 읍면동은 바로.....
경상북도 의성군 안계면으로 계산되었다.

2070년 추계 인구를 위처럼 테두리만 있는 사각형으로 바꾼 후, 가장 유사하다고 계산된 읍면동을 색칠해봤다. 결과는 아래 그림이다.

사실 아주 유사하다고 보기는 어렵다. 2070년에는 90세 이상 구간도 두터운 데 비해, 아직 그렇게 고령의 인구들이 많이 살고 있는 지역은 없다는 근본적인 차이 때문에, 아주 유사한 읍면동은 나타나지 않았던 것 같다.
그래도 경북 의성군 안계면이 3500여개중에 가장 분포가 가깝다고 계산된 이유는, 고령 인구가 두텁고 저연령으로 갈수록 줄어드는 형상이 2070년과 유사하기 때문인 것 같다.

그래도 안계면은 의성군에서, 의성군청이 있는 의성읍에 이어 초등학생 수는 두번째로 많다. 중심지에 있는 안계 초등학교에 170명이 다닌다. 안계면에는 중, 고등학교도 하나씩 있다. 앞의 경상북도 중 150개 읍면동 인구 분포에서 보았듯이 고령화의 기준에서는 훨씬 더 심각한, 그러니까 안계면보다 젊은 층이 바짝 마른 지역들이 다수 있다. 그나마 안계면은, 그러니까 중위 추계에 따른 우리나라의 2070년은 비록 고령화 되었지만 초등학교가 운영될만한 정도는 되는 것 같다.
여튼, 2070년 우리나라의 평균적인 고령화의 모습이 궁금하다면 의성군 안계면에 가보면 된다.
그럼 이번에는 2023년의 우리나라 평균적인 인구 분포를 담은 지역을 찾아보자.
역시 2023년의 분포와 3500여개 읍면동의 와서스타인 거리를 계산해봤다.
그래서 현재의 평균적인 우리나라 모습은......
강원도 춘천시 동내면에서 볼 수 있다.
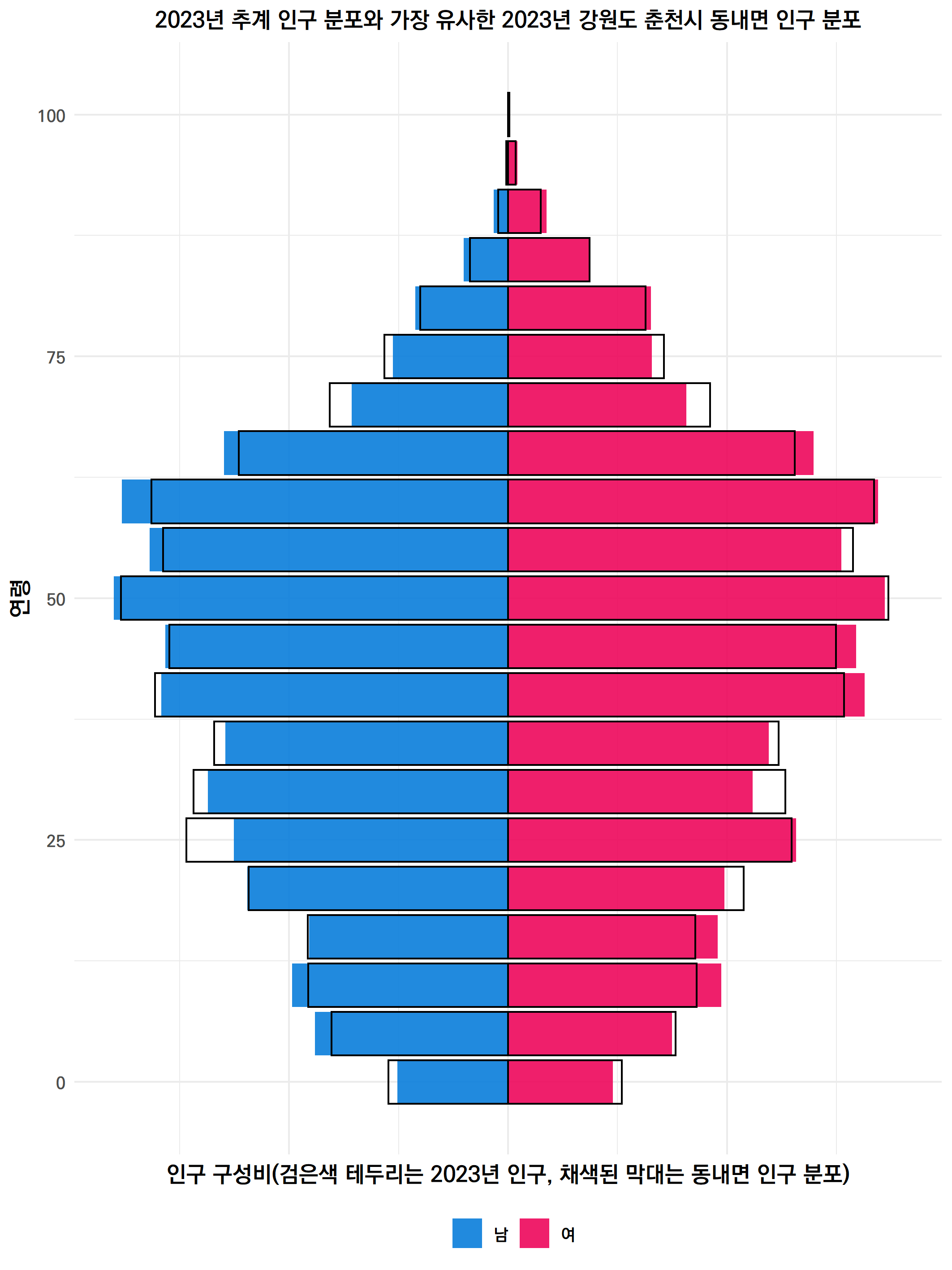
그래프에서 볼 수 있듯이, 이번에는 2023년의 인구 분포와 매우 흡사한 모습을 띤다.
수도권의 어떤 도시가 아니라 강원도 춘천의 면 지역이라는 점이 조금 놀라웠다.

조금 살펴보니 흥미로운 점들이 보인다.
넓은 지역의 북서쪽 일부에 아파트가 있는데 시대별로 지어진 단지들이 골고루 있다. 산지가 대부분이고, 고속도로가 가로지른다. 경사도가 낮은 지역에는 단층 건물들이 퍼져 있다. 서쪽 한가운데 파헤쳐진 지역은 2025년에 새로 입주할 아파트들이 지어지고 있다.
그 안에서 벌어지는 일들도 마치 우리나라의 평균적인 축소판 같다.
그럼 이번에는 현재에서 과거를 찾아보자.
1990년의 인구 분포와 가장 유사한 곳은?
전남 나주시 빛가람동이 나왔다.

그런데 가장 유사하긴 하지만 1990년의 인구 분포와는 근본적인 차이가 존재한다. 1990년에는 20세 전후의 인구가 가장 두터운데, 대학이 없는 빛가람동의 인구는 그와 유사하기 어렵기 때문이다. 1990년의 20대 대신 지금의 빛가람동은 40대가 많다. 그래도 15세 이하의 아이들은 많다.
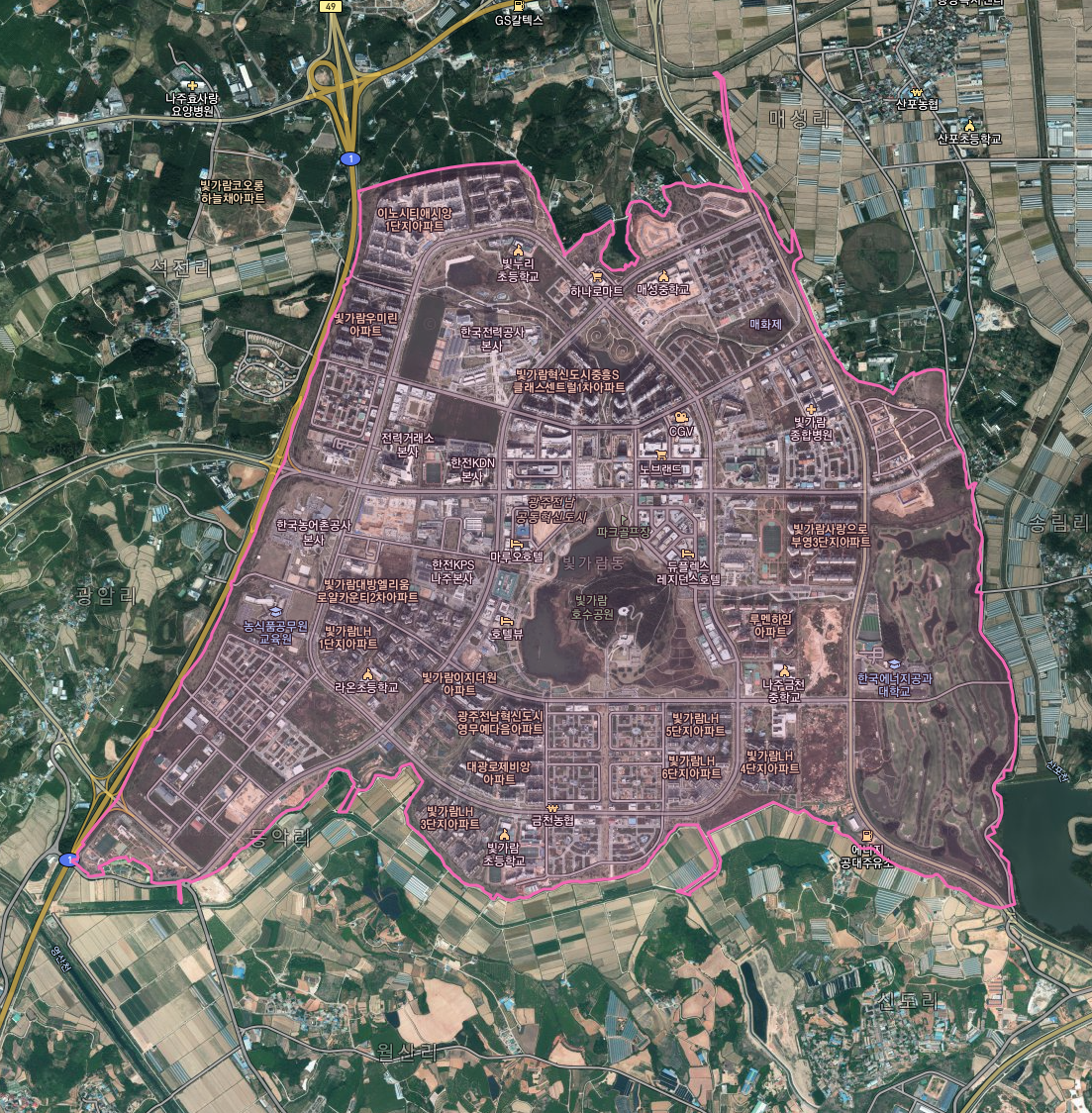
빛가람동은 혁신도시다. 한국 전력 본사와 신도시처럼 택지개발로 지어진 아파트단지들이 대부분이다.
이렇게 미래-현재-과거를 보니 이런저런 생각이 든다.
우리의 과거는 원도심 옆에 만든 신도시였고, 현재는 중소도시의 외곽지역이며, 미래는 면 규모의 비도시 지역이다.
이 세 지역은 2023년이라는 하나의 시간 안에 존재하기도 한다. 갑자기 신도시를 만들면 주변의 면과 읍에서 사람들이 이주해간다. 하나가 커질수록 다른 곳들은 줄어든다. 우리의 미래가 면 규모의 인구구성으로 향하는 까닭은 어쩌면 우리가 과거에 신도시를 열심히 만들었기 때문은 아닐까? 신도시를 닮은 인구 구성이 시간이 지남에 따라 면지역의 모습으로 되어간다는 점이 아이러니하다.
1980년부터 몇몇 시점과 가장 유사한 2023년의 지역들을 지도에 표시해봤다.

각 시점과 가장 가까운 읍면동 사이의 인구 분포는 아래에 차례대로 늘어놓았다.



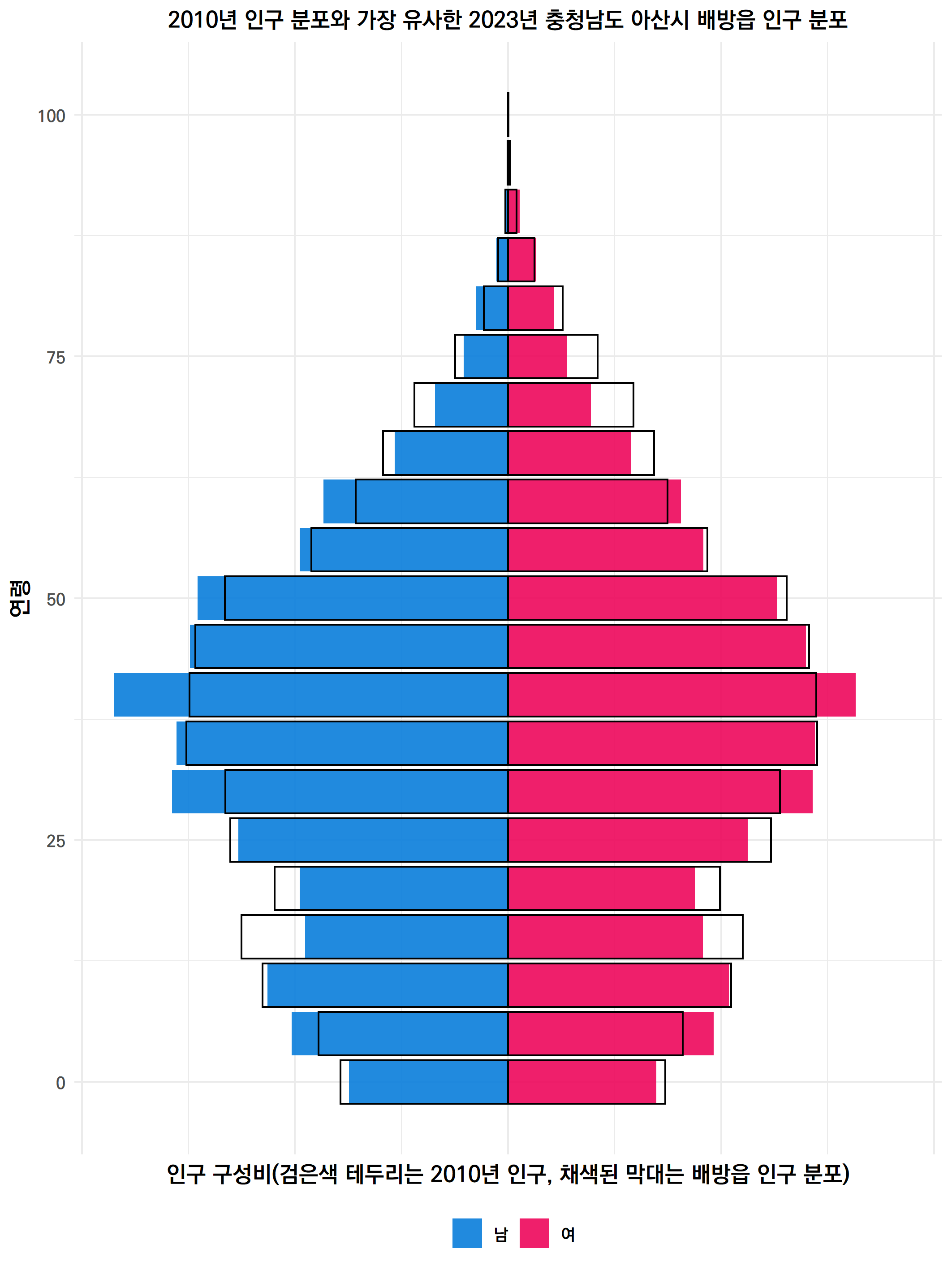




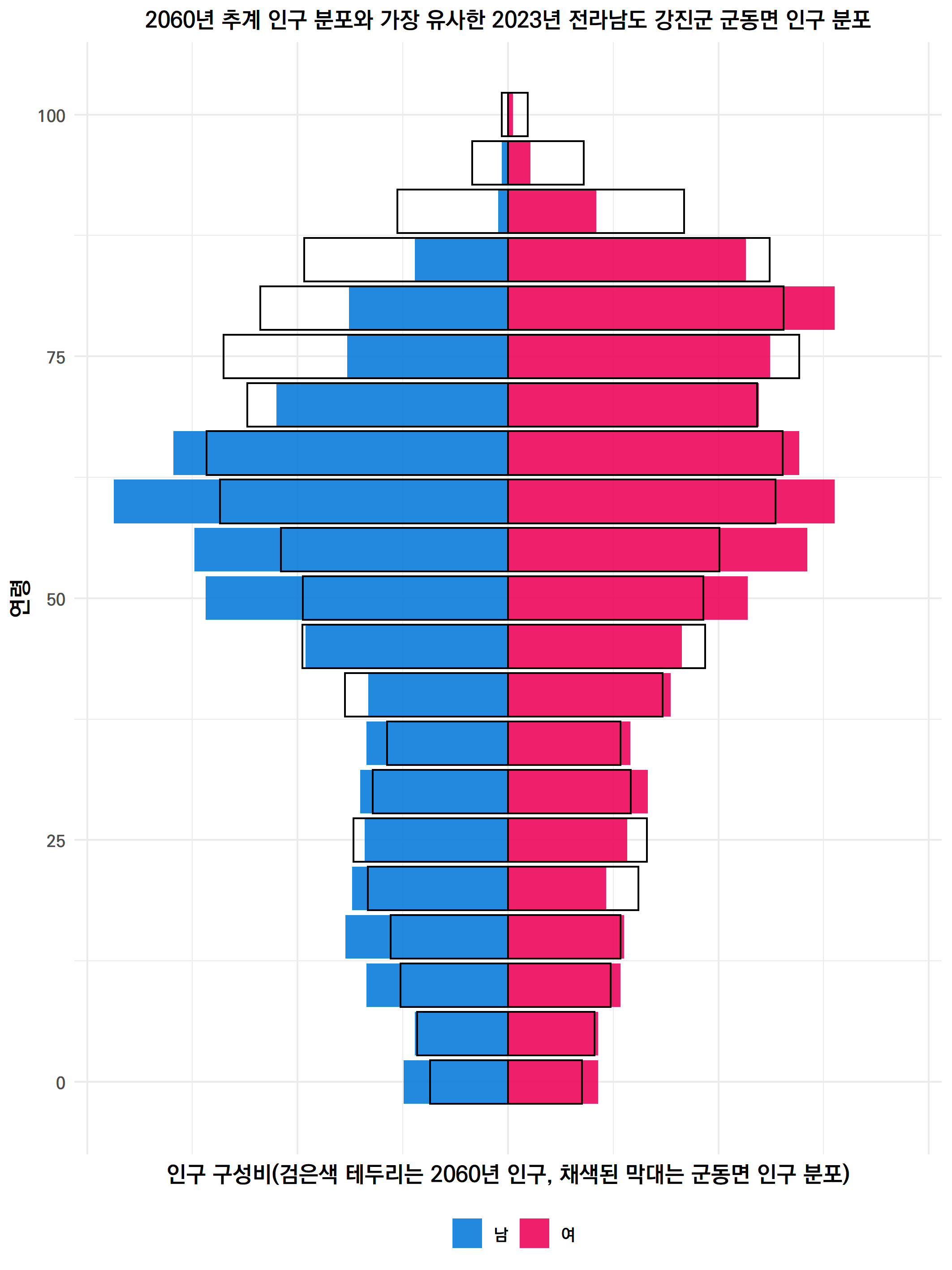
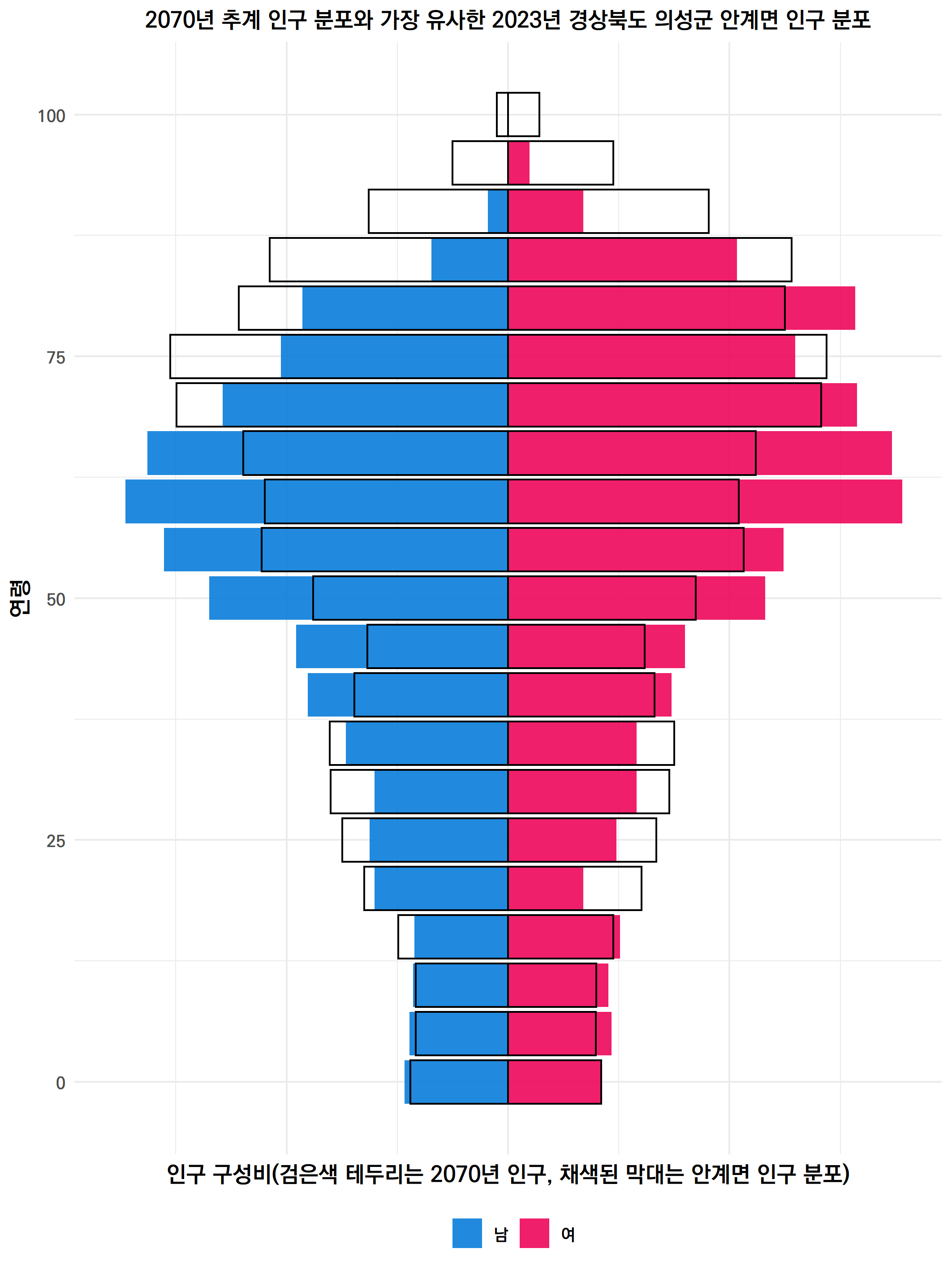
그림 그리는데 사용한 데이터와 코드는 아래에 있다.
[인구1925-2070.csv] 파일에서 1925-1990년은 총조사인구를, 1993-2022년은 통계청 연도별 주민등록 인구를, 2023년부터는 2020년 기준 중위추계인구를 사용했다.
[읍면동별인구202305.csv] 는 통계청의 월별 읍면동별 5세별 주민등록인구를 사용했다.
library(data.table)
library(ggplot2)
library(dplyr)
install.packages('transport')
library(transport)
# load packages
if(!require(foreach)) {
install.packages("foreach")
}
library(foreach)
if(!require(doParallel)) {
install.packages("doParallel")
}
library(doParallel)
install.packages("extrafont")
library(extrafont)
extrafont::font_import(pattern="KoPubWorld Dotum Bold.ttf", prompt=FALSE)
fonts()
fonttable()
loadfonts()
##읍면동별 인구 준비
sourceFolder <- "./"
system.time(emdpopu <- fread(paste0(sourceFolder, "읍면동별인구202305.csv"),
quote="\"",
encoding="UTF-8",
select = c(1,2,3,6,8),
colClasses = list(character = c(1,2,6),
integer=c(3,8)
#numeric = c(6,7)
),
col.names = c('emdcd','emdnm','age','gender','popu'),
sep = ",", header = TRUE, stringsAsFactors = FALSE, nThread = 20
)
)
emdpopu[, age:=age-5]
emdpopu[, gender:=substr(gender,1,1)]
setorder(emdpopu, emdcd, gender, age)
emdSplit <- split(emdpopu, by="emdcd")
popuSumEmd <- emdpopu %>% group_by(emdcd) %>% summarise(popu=sum(popu))
system.time(yearpopu <- fread(paste0(sourceFolder, "인구1925-2070.csv"),
quote="\"",
encoding="UTF-8",
select = c(3:93),
colClasses = list(#character = c(2,3),
integer=c(3:93)
#numeric = c(6,7)
),
#col.names = c('emdcd','emdnm','age','gender','popu'),
sep = "\t", header = TRUE, stringsAsFactors = FALSE, nThread = 20
)
)
#################################################################################
#################################################################################
#################################################################################
myCluster <- parallel::makeCluster(30)
doParallel::registerDoParallel(myCluster)
resultW <- foreach::foreach(index = 1:(length(yearpopu)),
#.export = c("yearpopu", "emdSplit"),
.combine = rbind) %dopar% {
library(data.table)
library(dplyr)
library(transport)
#index=1
final <- data.table()
popuThisYear <- data.table()
#availCount <- sum(!is.na(yearpopu[[index]]))
#subset <- yearpopu[1:availCount, n]
subset <- yearpopu[!is.na(yearpopu[[index]])][[index]]
subset
popuThisYear$popu <- subset
availCount <- length(subset)
popuSumYear<-sum(popuThisYear$popu)
popuThisYear[, popuRatio:=popu/popuSumYear]
thisYear <- as.integer(colnames(yearpopu)[index])
rows <- availCount
# costm 행렬 초기화
costm <- matrix(Inf, nrow = rows, ncol = rows)
# 1~21 사이의 이동비용 설정
# 1~21 사이의 이동비용 설정
for(i in 1:(rows/2)) {
for(j in 1:(rows/2)) {
costm[i,j] <- abs(i-j)+1
}
}
# 22~42 사이의 이동비용 설정
for(i in (rows/2+1):rows) {
for(j in (rows/2+1):rows) {
costm[i,j] <- abs(i-j)+1
}
}
for (i in c(1:length(emdSplit))) {
#i=1
data <- emdSplit[[i]]
male <- data[1:21, .(popu)]
female <- data[22:42, .(popu)]
if (rows<42) {
# 16행에 합산값을 대입합니다.
lastRow <- rows/2
sum_values <- sum(male[lastRow:21, popu])
male[lastRow, popu := sum_values]
male <- male[-((lastRow+1):21)]
sum_values <- sum(female[lastRow:21, popu])
female[lastRow, popu := sum_values]
female <- female[-((lastRow+1):21)]
}
newData<-rbindlist(list(male, female))
emdcd <- data$emdcd[[1]]
emdnm <- data$emdnm[[1]]
popuSum <- sum(newData$popu)
if (popuSum>0) {
newData[, popuRatio:=popu/popuSum]
temp <- data.frame(yearly = popuThisYear$popuRatio, emd = newData$popuRatio)
#temp[, diff:=(emd-yearly)*(emd-yearly)]
#distance = sqrt(sum(temp$diff))
distance <- wasserstein(temp[,1], temp[,2], costm = costm)
result <- data.table(year=thisYear, emdcd=emdcd, emdnm=emdnm, dist = distance)
final <-rbindlist(list(final, result))
}
}
return(final)
}
# 클러스터 중지
parallel::stopCluster(myCluster)
setorder(resultW, year, emdcd)
resultW <- resultW %>% left_join(popuSumEmd, by="emdcd")
fwrite(resultW, file=paste0(sourceFolder, "계산결과_와서스타인.tsv"), sep="\t")
new_df_W <- resultW %>%
filter(popu>=3000) %>%
group_by(year) %>%
arrange(desc(dist)) %>%
slice_head(n = 1) %>%
ungroup()
fwrite(new_df_W, file=paste0(sourceFolder, "계산결과_와서스타인_1위만.tsv"), sep="\t")
#################################################################################
############# 그래프 그리기 ########################
#################################################################################
fileName <- "coordinate_UTMK_이름포함.tsv"
admnm <- fread(fileName,
#quote="\"",
encoding="UTF-8",
select = c(2:3),
colClasses = list(character = c(2,3)
#integer=c(4:54)
#numeric = c(6,7)
),
#col.names = c('emdcd','emdnm','age','gender','popu'),
sep = "\t", header = TRUE, stringsAsFactors = FALSE, nThread = 20
)
setDT(new_df_W)
compGraph <- function(yearY) {
#yearY <- 1925
yearY <- as.integer(yearY)
emdcd <- new_df_W[year==yearY]$emdcd
emdpopuExt <- emdSplit[[emdcd]]
emdnm <- emdpopuExt$emdnm[1]
fullnm <- admnm[ADMCD==emdcd]$ADMNM
popusum <- sum(emdpopuExt$popu)
emdpopuExt[, popuRatio:=popu/popusum]
yearpopuExt <- emdpopuExt[, .(age, gender)]
yearpopuExt$popu <- yearpopu[[as.character(yearY)]]
yearpopuExt[is.na(popu), popu:=0]
popusum <- sum(yearpopuExt$popu)
yearpopuExt[, popuRatio:=popu/popusum]
# 데이터 전처리: 남성 인구는 음수로 변환하여 왼쪽으로 표시
emdpopuExt <- emdpopuExt %>%
mutate(popuRatio = if_else(gender == '남', -popuRatio, popuRatio))
# 데이터 전처리: 남성 인구는 음수로 변환하여 왼쪽으로 표시
yearpopuExt <- yearpopuExt %>%
mutate(popuRatio = if_else(gender == '남', -popuRatio, popuRatio))
# popuRatio의 부호를 바꾸고 factor로 변환
emdpopuExt[, gender := factor(gender, levels = c('남', '여'))]
yearpopuExt[, gender := factor(gender, levels = c('남', '여'))]
strTemp <- ifelse(yearY>2022," 추계","")
max_value <- max(abs(emdpopuExt$popuRatio), abs(yearpopuExt$popuRatio))
# 두 개의 데이터프레임을 사용하여 겹치는 그래프 생성
ggplot() +
geom_col(data = emdpopuExt, aes(x = age, y = popuRatio, fill = gender), position = "identity", alpha = 0.9) +
geom_col(data = yearpopuExt, aes(x = age, y = popuRatio), position = "identity", color = "black", fill = NA) +
coord_flip() +
scale_y_continuous(limits = c(-max_value, max_value)) +
scale_fill_manual(values = c("남" = "#097ddb", "여" = "#ed075b")) +
labs(title = paste0(yearY,"년",strTemp," 인구 분포와 가장 유사한 2023년 ",fullnm," 인구 분포"),
x = "연령", y = paste0("인구 구성비(검은색 테두리는 ",yearY,"년 인구, 채색된 막대는 ",emdnm," 인구 분포)")) +
theme_minimal() +
theme(text=element_text(family="KoPubWorldDotum Bold"),
plot.title = element_text(hjust = 0.5, size = rel(1.1)),
axis.title.x = element_text(size = rel(1.1)),
axis.title.y = element_text(size = rel(1.1)),
axis.text.x = element_blank(),
legend.position = "bottom",
legend.title = element_blank())
ggsave(paste0(sourceFolder, "이미지\\",yearY,"년_",fullnm,"인구.png"),
antialias = "default", width = 180, height = 240, unit = c("mm"), dpi = 300)
#ggsave(paste0(sourceFolder, yearY))
#fwrite(emdpopuExt, file=paste0(sourceFolder, "2070.tsv"), sep="\t")
}
column_names <- names(yearpopu)
for (year in column_names) {
compGraph(year)
}
#################################################################################
################ 3500여개를 시군구별로 150장씩 그리기 ###########################
#################################################################################
setDT(admnm)
admnm[, ADMCD := as.character(ADMCD)]
# 각 emdcd에 대한 데이터프레임을 리스트에서 합칩니다.
emdpopuExt_combined <- rbindlist(emdSplit, idcol = "emdcd")
emdpopuExt_combined$emdcd <- as.factor(emdpopuExt_combined$emdcd)
emdpopuExt_combined[gender == "남", popuRatio := popuRatio * -1]
emdpopuExt_combined <- emdpopuExt_combined[,2:7]
# emdcd에 매칭되는 fullnm을 가져오기
emdpopuExt_combined_sub <- merge(emdpopuExt_combined, admnm%>%select(ADMCD, ADMNM), by.x = "emdcd", by.y = "ADMCD", all.x = TRUE)
name_list <- emdpopuExt_combined_sub[, .(ADMNM = first(ADMNM)), by = emdcd][, setNames(ADMNM, emdcd)]
extra_emdcd <- 9999900000:9999900150
extra_admnm <- rep("", length(extra_emdcd))
extra_pairs <- setNames(extra_admnm, as.character(extra_emdcd))
name_list <- c(name_list, extra_pairs)
# 한 페이지에 그릴 emdcd의 개수 설정
graphs_per_page <- 150
# emdcd를 substr(emdcd,1,2)로 나누어 집합을 생성합니다.
emdpopuExt_combined$emdcd_group <- substr(emdpopuExt_combined$emdcd, 1, 2)
uniqueCD <- unique(emdpopuExt_combined$emdcd_group)
# 집합별로 페이지 수를 계산합니다.
total_pages_per_group <- ceiling(length(unique(emdpopuExt_combined$emdcd_group)) / graphs_per_page)
for (iii in c(1:length(uniqueCD))) {
# 현재 집합 페이지에 해당하는 집합 선택
# iii <- 1
thisCD <- uniqueCD[iii]
# 선택한 집합에 해당하는 데이터만 선택
data_this_group <- emdpopuExt_combined[emdcd_group==thisCD]
# 집합 내에서 페이지 수를 계산합니다.
total_pages_in_group <- ceiling(length(unique(data_this_group$emdcd)) / graphs_per_page)
sidocd <- paste0(substr(data_this_group$emdcd[[1]],1,2),"00000000")
sidonm <- admnm[ADMCD==sidocd]$ADMNM
for (page in c(1:total_pages_in_group)) {
# 현재 페이지에 해당하는 emdcd 선택
#page<-2
emdcds_this_page <- unique(data_this_group$emdcd)[((page - 1) * graphs_per_page + 1):(page * graphs_per_page)]
# 선택한 emdcd에 대한 데이터만 선택
data_this_page <- data_this_group[emdcd %in% emdcds_this_page, ]
max_value <- max(data_this_page$popuRatio, na.rm = TRUE)
# 필요한 dummy 데이터 개수 계산
dummy_count <- 150-length(unique(data_this_page$emdcd))
if (dummy_count>0) {
# dummy 데이터 생성
emdcd0 <- data_this_page$emdcd[[1]]
dummy_data <- data_this_page[emdcd==emdcd0]
dummy_data[, popuRatio:=0]
dummy_data[, emdcd:= "9999900000"]
df_list <- lapply(1:dummy_count, function(i) {
copied_df <- copy(dummy_data)
copied_df[, emdcd:=as.character(as.numeric(emdcd)+i)]
return (copied_df)
})
combined_df <- rbindlist(df_list)
# 데이터 합치기
data_this_page <- rbindlist(list(data_this_page, combined_df))
}
# 그래프 그리기
p <- ggplot(data_this_page, aes(x = age, y = popuRatio, fill = gender)) +
geom_col(position = "identity", alpha = 0.9) +
coord_flip() +
scale_y_continuous(limits = c(-max_value, max_value)) +
scale_fill_manual(values = c("남" = "#097ddb", "여" = "#ed075b")) +
facet_wrap(~ emdcd, labeller = as_labeller(name_list), ncol = 10, nrow = 15) +
labs(title = paste0("2023년 ",sidonm," 인구 분포"),
x = "연령", y = "인구 분포") +
theme_minimal() +
theme(text=element_text(family="KoPubWorldDotum Bold"),
plot.title = element_text(hjust = 0.5, size = rel(1.3)),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.text.x = element_blank(),
axis.text.y = element_blank(),
strip.text = element_text(size = rel(0.3)),
legend.position = "none")
# 그래프를 PNG 파일로 저장
ggsave(paste0(sourceFolder, "2023년 전국\\2023년 인구 분포_",sidonm,"_", page, ".png"),
plot = p, antialias = "default", width = 180, height = 240, unit = "mm", dpi = 300)
}
}'Content' 카테고리의 다른 글
| 새로 만드는 수도권 지하철은 접근성 지형도를 어떻게 바꿔놓을까 - 2. 들여다보기 (0) | 2026.05.04 |
|---|---|
| Urban Density Profiler : 경계 너머 도시 들여다보기 (1) | 2026.04.02 |
| <화물차를 쉬게 하라> - 2. 타이어 같은 운행 기록의 표현 (0) | 2023.02.15 |
| 시군구별 연령별 인구 변화 시각화(2000~2020) (4) | 2021.12.29 |
| 대한민국 시군구 인구 변화 시각화(1975~2020) (3) | 2021.12.29 |



