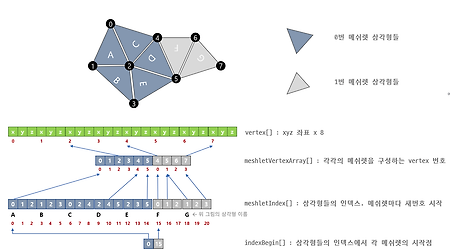
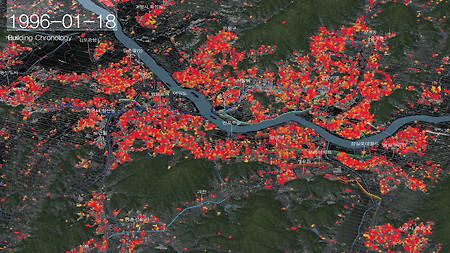
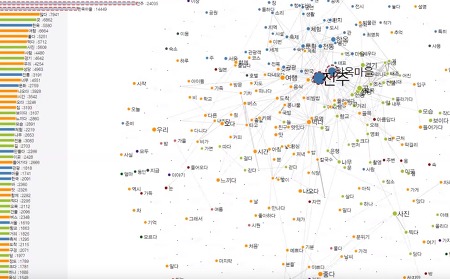
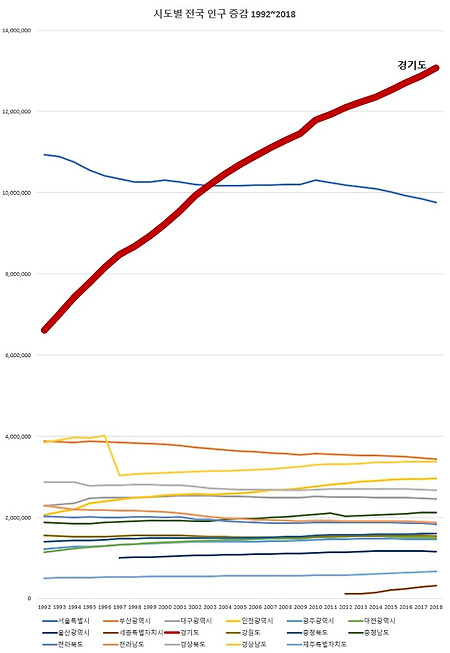
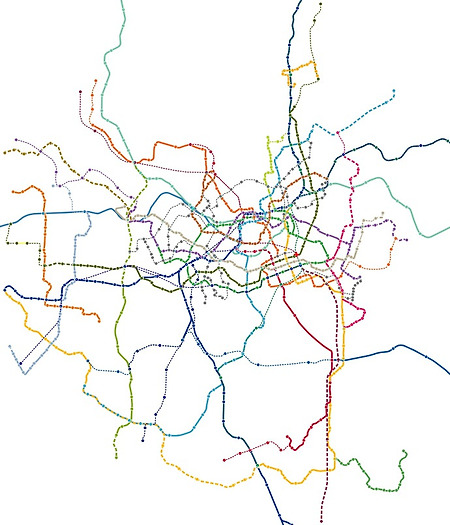
Content
2019. 11. 1.
서울 공공자전거 따릉이 대여반납량 순위
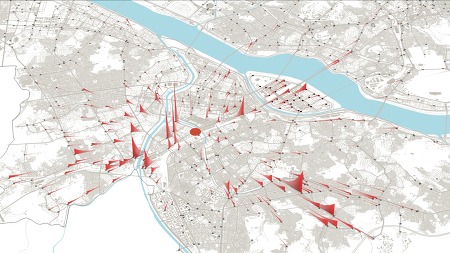
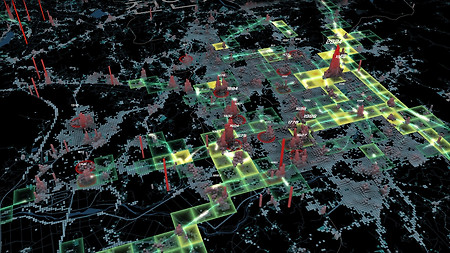
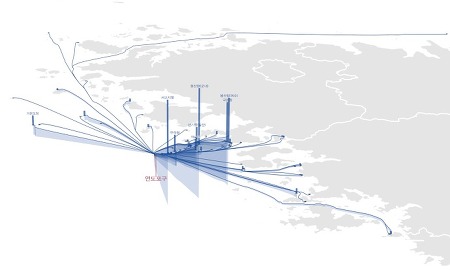
2018년 6월 1일부터 2019년 5월 31일까지 365일 동안의 서울 전역 따릉이 대여반납 회수를 합산해봤다. 특정 대여소에서 대여 2회, 반납 5회가 이루어졌다면 총 2+5=7회의 대여반납량으로 계산하였다. 즉, 어떤 사람이 따릉이를 한 번 이용하였다면 어딘가에 대여 1회, 반납 1회 했을 것이므로 서울 전체로 볼 때 총 2회의 대여반납량을 발생시기케 된다. 그럼 간단히 순위만 보자. 아래 그림에서 빨간 동그라미는 순위 대여소, 그리고 삼각형들은 순위 대여소에서 대여한 자전거를 반납한 장소, 혹은 반납한 자전거를 대여한 장소들의 대여반납량을 표시한 것이다. 1위 여의나루역 1번출구 앞(207번 대여소), 총 158,194회 물론, 같은 여의도 안에 있는 대여소와의 상호작용량이 가장 많지만, 그 외에..